sed是一种流编辑器,它是文本处理中非常好的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件,可以将数据行进行替换、删除、新增、选取等特定工作,简化对文件的反复操作,编写转换程序等。
命令格式
sed的命令格式:sed [options] 'command' file(s);
sed的脚本格式:sed [options] -f scriptfile file(s);
选项
-e :直接在命令行模式上进行sed动作编辑,此为默认选项;
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作;
-i :直接修改文件内容;
-n :只打印模式匹配的行;
-r :支持扩展表达式;
-h或--help:显示帮助;
-V或--version:显示版本信息。
参数
文件:指定待处理的文本文件列表。
sed常用命令
a\ 在当前行下面插入文本;
i\ 在当前行上面插入文本;
c\ 把选定的行改为新的文本;
d 删除,删除选择的行;
D 删除模板块的第一行;
s 替换指定字符;
h 拷贝模板块的内容到内存中的缓冲区;
H 追加模板块的内容到内存中的缓冲区;
g 获得内存缓冲区的内容,并替代当前模板块中的文本;
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面;
l 列表不能打印字符的清单;
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令;
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码;
p 打印模板块的行。 P(大写) 打印模板块的第一行;
q 退出Sed;
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾;
r file 从file中读行;
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾;
w file 写并追加模板块到file末尾;
W file 写并追加模板块的第一行到file末尾;
! 表示后面的命令对所有没有被选定的行发生作用;
= 打印当前行号;
# 把注释扩展到下一个换行符以前;
sed替换标记
g 表示行内全面替换;
p 表示打印行;
w 表示把行写入一个文件;
x 表示互换模板块中的文本和缓冲区中的文本;
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式);
\1 子串匹配标记;
& 已匹配字符串标记;
sed元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行;
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行;
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d;
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行;
[] 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed;
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行;
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers;
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**;
\< 匹配单词的开始,如:/\
\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行;
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行;
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行;
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行;
sed用户实例
替换操作:s命令
替换文本中的字符串:
sed 's/book/books/' file
-n选项和p命令一起使用表示只打印那些发生替换的行:
sed -n 's/test/TEST/p' file
直接编辑文件选项-i,会匹配file文件中每一行的第一个book替换为books
sed -i 's/book/books/g' file
全面替换标记g
使用后缀 /g 标记会替换每一行中的所有匹配:
sed 's/book/books/g' file
当需要从第N处匹配开始替换时,可以使用 /Ng:
echo sksksksksksk | sed 's/sk/SK/2g'
skSKSKSKSKSK
echo sksksksksksk | sed 's/sk/SK/3g'
skskSKSKSKSK
echo sksksksksksk | sed 's/sk/SK/4g'
skskskSKSKSK
定界符
以上命令中字符 / 在sed中作为定界符使用,也可以使用任意的定界符
sed 's:test:TEXT:g'
sed 's|test|TEXT|g'
定界符出现在样式内部时,需要进行转义:
sed 's/\/bin/\/usr\/local\/bin/g'
删除操作:d命令
删除空白行:
sed '/^$/d' file
删除文件的第2行:
sed '2d' file
删除文件的第2行到末尾所有行:
sed '2,$d' file
删除文件最后一行:
sed '$d' file
删除文件中所有开头是test的行:
sed '/^test/'d file
已匹配字符串标记&
正则表达式 \w\+ 匹配每一个单词,使用 [&] 替换它,& 对应于之前所匹配到的单词:
echo this is a test line | sed 's/\w\+/[&]/g'
[this] [is] [a] [test] [line]
所有以192.168.0.1开头的行都会被替换成它自已加localhost:
sed 's/^192.168.0.1/&localhost/' file 192.168.0.1localhost
子串匹配标记\1
匹配给定样式的其中一部分:
echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/'
this is 7 in a number
命令中 digit 7,被替换成了 7。样式匹配到的子串是 7,\(..\) 用于匹配子串,对于匹配到的第一个子串就标记为 \1,依此类推匹配到的第二个结果就是 \2,例如:
echo aaa BBB | sed 's/\([a-z]\+\) \([A-Z]\+\)/\2 \1/'
BBB aaa
love被标记为1,所有loveable会被替换成lovers,并打印出来:
sed -n 's/\(love\)able/\1rs/p' file
组合多个表达式
sed '表达式' | sed '表达式' 等价于:
sed '表达式; 表达式'
引用
sed表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号。
test=hello
echo hello WORLD | sed "s/$test/HELLO"
HELLO WORLD
选定行的范围:,(逗号)
所有在模板test和check所确定的范围内的行都被打印:
sed -n '/test/,/check/p' file
打印从第5行开始到第一个包含以test开始的行之间的所有行:
sed -n '5,/^test/p' file
对于模板test和west之间的行,每行的末尾用字符串aaa bbb替换:
sed '/test/,/west/s/$/aaa bbb/' file
多点编辑:e命令
-e选项允许在同一行里执行多条命令:
sed -e '1,5d' -e 's/test/check/' file
上面sed表达式的第一条命令删除1至5行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
和 -e 等价的命令是 –expression:
sed --expression='s/test/check/' --expression='/love/d' file
从文件读入:r命令
file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面:
sed '/test/r file' filename
写入文件:w命令
在example中所有包含test的行都被写入file里:
sed -n '/test/w file' example
追加(行下):a\命令
将 this is a test line 追加到 以test 开头的行后面:
sed '/^test/a\this is a test line' file
在 test.conf 文件第2行之后插入 this is a test line:
sed -i '2a\this is a test line' test.conf
插入(行上):
i\命令 将 this is a test line 追加到以test开头的行前面:
sed '/^test/i\this is a test line' file
在test.conf文件第5行之前插入this is a test line:
sed -i '5i\this is a test line' test.conf
下一个:n命令
如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续:
sed '/test/{ n; s/aa/bb/; }' file
变形:y命令
把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令:
sed '1,10y/abcde/ABCDE/' file
退出:q命令
打印完第10行后,退出sed sed ’10q’ file 保持和获取:h命令和G命令 在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
sed -e '/test/h' -e '$G' file
在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换:
sed -e '/test/h' -e '/check/x' file
脚本scriptfile
sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
sed [options] -f scriptfile file(s)
打印奇数行或偶数行
方法1:
sed -n 'p;n' test.txt #奇数行 sed -n 'n;p' test.txt #偶数行
方法2:
sed -n '1~2p' test.txt #奇数行 sed -n '2~2p' test.txt #偶数行
打印匹配字符串的下一行
grep -A 1 SCC URFILE
sed -n '/SCC/{n;p}' URFILE
awk '/SCC/{getline; print}' URFILE
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
- -e<script>或–expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或–file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或–help 显示帮助。
- -n或–quiet或–silent 仅显示script处理后的结果。
- -V或–version 显示版本信息。
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
实例
首先查看testfile中的内容如下:
$ cat testfile #查看testfile 中的内容
HELLO LINUX!
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
使用sed命令后,输出结果如下:
$ sed -e 4a\newline testfile #使用sed 在第四行后添加新字符串
HELLO LINUX! #testfile文件原有的内容
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
newline
以行为单位的新增/删除
将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除!
[root@www ~]# nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
.....(后面省略).....
sed 的动作为 ‘2,5d’ ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行罗~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 ” 两个单引号括住喔!
只要删除第 2 行
nl /etc/passwd | sed '2d'
要删除第 3 到最后一行
nl /etc/passwd | sed '3,$d'
在第二行后(亦即是加在第三行)加上『drink tea?』字样!
[root@www ~]# nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
那如果是要在第二行前
nl /etc/passwd | sed '2i drink tea'
如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or ….. 与 drink beer?
[root@www ~]# nl /etc/passwd | sed '2a Drink tea or ......\
> drink beer ?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ......
drink beer ?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.....(后面省略).....
每一行之间都必须要以反斜杠『 \ 』来进行新行的添加喔!所以,上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。
以行为单位的替换与显示
将第2-5行的内容取代成为『No 2-5 number』呢?
[root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
.....(后面省略).....
透过这个方法我们就能够将数据整行取代了!
仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~]# nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。
数据的搜寻并显示
搜索 /etc/passwd有root关键字的行
nl /etc/passwd | sed '/root/p'
1 root:x:0:0:root:/root:/bin/bash
1 root:x:0:0:root:/root:/bin/bash
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
3 bin:x:2:2:bin:/bin:/bin/sh
4 sys:x:3:3:sys:/dev:/bin/sh
5 sync:x:4:65534:sync:/bin:/bin/sync
....下面忽略
如果root找到,除了输出所有行,还会输出匹配行。
使用-n的时候将只打印包含模板的行。
nl /etc/passwd | sed -n '/root/p'
1 root:x:0:0:root:/root:/bin/bash
数据的搜寻并删除
删除/etc/passwd所有包含root的行,其他行输出
nl /etc/passwd | sed '/root/d'
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
3 bin:x:2:2:bin:/bin:/bin/sh
....下面忽略
#第一行的匹配root已经删除了
数据的搜寻并执行命令
搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}'
1 root:x:0:0:root:/root:/bin/blueshell
最后的q是退出。
数据的搜寻并替换
除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代。基本上 sed 的搜寻与替代的与 vi 相当的类似!他有点像这样:
sed 's/要被取代的字串/新的字串/g'
sed -i 's/^/add chnroute &/g' /opt/de_GWD/chnrouteSET #在每行首加入“add chnroute”
先观察原始信息,利用 /sbin/ifconfig 查询 IP
root@ali-qss:~# ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.24.95.96 netmask 255.255.240.0 broadcast 172.24.95.255
inet6 fe80::216:3eff:fe10:3c2e prefixlen 64 scopeid 0x20<link>
ether 00:16:3e:10:3c:2e txqueuelen 1000 (Ethernet)
RX packets 53156928 bytes 18406554587 (17.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 38893956 bytes 3821418928 (3.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
.....(以下省略).....
本机的ip是192.168.1.100。
将 IP 前面的部分予以删除
root@ali-qss:~# ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g'
172.24.95.96 netmask 255.255.240.0 broadcast 172.24.95.255
接下来则是删除后续的部分,亦即: netmask 255.255.240.0 broadcast 172.24.95.255
将 IP 后面的部分予以删除
ifconfig eth0 | grep 'inet ' | sed 's/^.*inet //g' | sed 's/netmask.*$//g'
192.168.1.100
多点编辑
一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell
nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/'
1 root:x:0:0:root:/root:/bin/blueshell
2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh
-e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。
直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试! 我们还是使用文件 regular_express.txt 文件来测试看看吧!
regular_express.txt 文件内容如下:
[root@www ~]# cat regular_express.txt
runoob.
google.
taobao.
facebook.
zhihu-
weibo-
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 !
[root@www ~]# sed -i 's/\.$/\!/g' regular_express.txt
sed -i 's/
[root@www ~]# cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
:q:q利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test:
[root@www ~]# sed -i '$a # This is a test' regular_express.txt
[root@www ~]# cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
# This is a test
由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test!
用sed命令在行首或行尾添加字符的命令有以下几种:
假设处理的文本为test.file

在每行的头添加字符,比如”HEAD”,命令如下:
sed ‘s/^/HEAD&/g’ test.file
在每行的行尾添加字符,比如“TAIL”,命令如下:
sed ‘s/$/&TAIL/g’ test.file
运行结果如下图:

几点说明:
1.”^”代表行首,”$”代表行尾
2.’s/$/&TAIL/g’中的字符g代表每行出现的字符全部替换,如果想在特定字符处添加,g就有用了,否则只会替换每行第一个,而不继续往后找了
例:

3.如果想导出文件,在命令末尾加”> outfile_name”;如果想在原文件上更改,添加选项”-i”,如(这里的-i,可以理解为其他命令执行后的结果重定向到原文件,所以-n p等参数会影响-i的效果)

4.也可以把两条命令和在一起,在test.file的每一行的行头和行尾分别添加字符”HEAD”、“TAIL”,命令:sed ‘/./{s/^/HEAD&/;s/$/&TAIL/}’ test.file
以上其实都还OK,昨天花太多时间,主要因为被处理的文件是用Mysql从数据库提取的结果导出来的,别人给我之后我就直接处理,太脑残了= -我一直有点怀疑之所以结果不对,有可能是windows和linux换行的问题,可是因为对sed不熟,就一直在搞sed。。。。。。。
众所周知(= -),window和linux的回车换行之云云,如果你知道了,跳过这一段,不知道,读一下呗:
Unix系统里,每行结尾只有“<换行>”,即“\n”;Windows系统里面,每行结尾是“<换行><回 车>”,即“\n\r”。一个直接后果是,Unix系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix下打开的话,在每行的结尾可能会多出一个^M符号。
好了,所以我的问题就出在被处理的文件的每行末尾都有^M符号,而这通常是看不出来的。可以用”cat -A test.file”命令查看。因此当我想在行尾添加字符的时候,它总是添加在行首且会覆盖掉原来行首的字符。
要把文件转换一下,有两种方法:
1.命令dos2unix test.file
2.去掉”\r” ,用命令sed -i ‘s/\r//’ test.file
###################################
二、Sed练习
1,删除文件每行的第一个字符。
sed -n ‘s/^.//gp’ /etc/passwd
sed -nr ‘s/(.)(.*)/\2/p’ /etc/passwd
2,删除文件每行的第二个字符。
sed -nr ‘s/(.)(.)(.*)/\1\3/p’ /etc/passwd
3,删除文件每行的最后一个字符。
sed -nr ‘s/.$//p’ /etc/passwd
sed -nr ‘s/(.*)(.)/\1/p’ /etc/passwd
4,删除文件每行的倒数第二个字符。
sed -nr ‘s/(.*)(.)(.)/\1\3/p’ /etc/passwd
5,删除文件每行的第二个单词。
sed -nr ‘s/([^a-Z]*)([a-Z]+)([^a-Z]+)([a-Z]+)(.*)/\1\2\3\5/p’ /etc/passwd
6,删除文件每行的倒数第二个单词。
sed -nr ‘s/(.*)([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]*)/\1\2\4\5\6/p’ /etc/samba/smb.conf
7,删除文件每行的最后一个单词。
sed -nr ‘s/(.*)([^a-Z]+)([a-Z]+)([^a-Z]*)/\1\2\4/p’ /etc/samba/smb.conf
8,交换每行的第一个字符和第二个字符。
sed -nr ‘s/(.)(.)(.*)/\2\1\3/p’ /etc/passwd
9,交换每行的第一个单词和第二个单词。
sed -nr ‘s/([^a-Z]*)([a-Z]+)([^a-Z]+)([a-Z]+)(.*)/\1\4\3\2\5/p’ /etc/samba/smb.conf
10,交换每行的第一个单词和最后一个单词。
sed -nr ‘s/([^a-Z]*)([a-Z]+)([^a-Z]+)([a-Z]+)(.*)/\1\4\3\2\5/p’ /etc/passwd
11,删除一个文件中所有的数字。
sed ‘s/[0-9]*//g’ /etc/passwd
12,删除每行开头的所有空格。
sed -n ‘s/^\ *//p’ /etc/samba/smb.conf
sed -nr ‘s/( *)(.*)/\2/p’ testp
13,用制表符替换文件中出现的所有空格。
sed -n ‘s/\ /\t/gp’ pass
14,把所有大写字母用括号()括起来。
sed -nr ‘s/([A-Z])/(&)/gp’ testp
sed -n ‘s/[A-Z]/(&)/gp’ testp
15,打印每行3次。
sed ‘p;p’ pass
16,隔行删除。
sed -n ‘1~2p’ pass
17,把文件从第22行到第33行复制到第44行后面。
sed ‘1,21h;22h;23,33H;44G’ pass
18,把文件从第22行到第33行移动到第44行后面。
sed ’22{h;d};23,33{H;d};44G’ pass
19,只显示每行的第一个单词。
sed -nr ‘s/([^a-Z]*)([a-Z]+)([^a-Z]+)(.*)/\2/p’ /etc/passwd
20,打印每行的第一个单词和第三个单词。
sed -nr ‘s/([^a-Z]*)([a-Z]+)([^a-Z]+)([a-Z]+)([^a-Z]+)([a-Z]+)(.*)/\2–\4/p’ /etc/passwd
21,将格式为 mm/yy/dd 的日期格式换成 mm;yy;dd
date +%m/%Y/%d |sed -n ‘s#/#;#gp’
22, 逆向输出
cat a.txt
ABC
DEF
XYZ
输出样式变成
XYZ
DEF
ABC




 -a 追加写入,将内容追加到上次内容之后
-a 追加写入,将内容追加到上次内容之后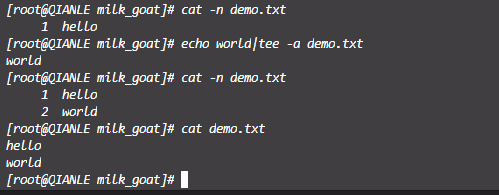 ECHO命令是大家都熟悉的DOS批处理命令的一条子命令,但它的一些功能和用法也许你并不是全都知道,不信你瞧:
ECHO命令是大家都熟悉的DOS批处理命令的一条子命令,但它的一些功能和用法也许你并不是全都知道,不信你瞧:

