使用示例
根据对应的操作系统及架构,从 Release 页面下载最新版本的程序。
将 frps 及 frps.ini 放到具有公网 IP 的机器上。
将 frpc 及 frpc.ini 放到处于内网环境的机器上。
通过 ssh 访问公司内网机器
- 修改 frps.ini 文件,这里使用了最简化的配置:
# frps.ini
[common]
bind_port = 7000
- 启动 frps:
./frps -c ./frps.ini
- 修改 frpc.ini 文件,假设 frps 所在服务器的公网 IP 为 x.x.x.x;
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = 6000
- 启动 frpc:
./frpc -c ./frpc.ini
- 通过 ssh 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@x.x.x.x
通过自定义域名访问部署于内网的 web 服务
有时想要让其他人通过域名访问或者测试我们在本地搭建的 web 服务,但是由于本地机器没有公网 IP,无法将域名解析到本地的机器,通过 frp 就可以实现这一功能,以下示例为 http 服务,https 服务配置方法相同, vhost_http_port 替换为 vhost_https_port, type 设置为 https 即可。
- 修改 frps.ini 文件,设置 http 访问端口为 8080:
# frps.ini
[common]
bind_port = 7000
vhost_http_port = 8080
- 启动 frps;
./frps -c ./frps.ini
- 修改 frpc.ini 文件,假设 frps 所在的服务器的 IP 为 x.x.x.x,local_port 为本地机器上 web 服务对应的端口, 绑定自定义域名
www.yourdomain.com:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[web]
type = http
local_port = 80
custom_domains = www.yourdomain.com
- 启动 frpc:
./frpc -c ./frpc.ini
- 将
www.yourdomain.com 的域名 A 记录解析到 IP x.x.x.x,如果服务器已经有对应的域名,也可以将 CNAME 记录解析到服务器原先的域名。
- 通过浏览器访问
http://www.yourdomain.com:8080 即可访问到处于内网机器上的 web 服务。
转发 DNS 查询请求
DNS 查询请求通常使用 UDP 协议,frp 支持对内网 UDP 服务的穿透,配置方式和 TCP 基本一致。
- 修改 frps.ini 文件:
# frps.ini
[common]
bind_port = 7000
- 启动 frps:
./frps -c ./frps.ini
- 修改 frpc.ini 文件,设置 frps 所在服务器的 IP 为 x.x.x.x,转发到 Google 的 DNS 查询服务器
8.8.8.8 的 udp 53 端口:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[dns]
type = udp
local_ip = 8.8.8.8
local_port = 53
remote_port = 6000
- 启动 frpc:
./frpc -c ./frpc.ini
- 通过 dig 测试 UDP 包转发是否成功,预期会返回
www.google.com 域名的解析结果:
dig @x.x.x.x -p 6000 www.google.com
转发 Unix域套接字
通过 tcp 端口访问内网的 unix域套接字(例如和 docker daemon 通信)。
frps 的部署步骤同上。
- 启动 frpc,启用
unix_domain_socket 插件,配置如下:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[unix_domain_socket]
type = tcp
remote_port = 6000
plugin = unix_domain_socket
plugin_unix_path = /var/run/docker.sock
- 通过 curl 命令查看 docker 版本信息
curl http://x.x.x.x:6000/version
对外提供简单的文件访问服务
通过 static_file 插件可以对外提供一个简单的基于 HTTP 的文件访问服务。
frps 的部署步骤同上。
- 启动 frpc,启用
static_file 插件,配置如下:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[test_static_file]
type = tcp
remote_port = 6000
plugin = static_file
# 要对外暴露的文件目录
plugin_local_path = /tmp/file
# 访问 url 中会被去除的前缀,保留的内容即为要访问的文件路径
plugin_strip_prefix = static
plugin_http_user = abc
plugin_http_passwd = abc
- 通过浏览器访问
http://x.x.x.x:6000/static/ 来查看位于 /tmp/file 目录下的文件,会要求输入已设置好的用户名和密码。
为本地 HTTP 服务启用 HTTPS
通过 https2http 插件可以让本地 HTTP 服务转换成 HTTPS 服务对外提供。
- 启用 frpc,启用
https2http 插件,配置如下:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[test_htts2http]
type = https
custom_domains = test.yourdomain.com
plugin = https2http
plugin_local_addr = 127.0.0.1:80
# HTTPS 证书相关的配置
plugin_crt_path = ./server.crt
plugin_key_path = ./server.key
plugin_host_header_rewrite = 127.0.0.1
- 通过浏览器访问
https://test.yourdomain.com 即可。
安全地暴露内网服务
对于某些服务来说如果直接暴露于公网上将会存在安全隐患。
使用 stcp(secret tcp) 类型的代理可以避免让任何人都能访问到要穿透的服务,但是访问者也需要运行另外一个 frpc。
以下示例将会创建一个只有自己能访问到的 ssh 服务代理。
frps 的部署步骤同上。
- 启动 frpc,转发内网的 ssh 服务,配置如下,不需要指定远程端口:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[secret_ssh]
type = stcp
# 只有 sk 一致的用户才能访问到此服务
sk = abcdefg
local_ip = 127.0.0.1
local_port = 22
- 在要访问这个服务的机器上启动另外一个 frpc,配置如下:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[secret_ssh_visitor]
type = stcp
# stcp 的访问者
role = visitor
# 要访问的 stcp 代理的名字
server_name = secret_ssh
sk = abcdefg
# 绑定本地端口用于访问 ssh 服务
bind_addr = 127.0.0.1
bind_port = 6000
- 通过 ssh 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@127.0.0.1
点对点内网穿透
frp 提供了一种新的代理类型 xtcp 用于应对在希望传输大量数据且流量不经过服务器的场景。
使用方式同 stcp 类似,需要在两边都部署上 frpc 用于建立直接的连接。
目前处于开发的初级阶段,并不能穿透所有类型的 NAT 设备,所以穿透成功率较低。穿透失败时可以尝试 stcp 的方式。
- frps 除正常配置外需要额外配置一个 udp 端口用于支持该类型的客户端:
- 启动 frpc,转发内网的 ssh 服务,配置如下,不需要指定远程端口:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[p2p_ssh]
type = xtcp
# 只有 sk 一致的用户才能访问到此服务
sk = abcdefg
local_ip = 127.0.0.1
local_port = 22
- 在要访问这个服务的机器上启动另外一个 frpc,配置如下:
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
[p2p_ssh_visitor]
type = xtcp
# xtcp 的访问者
role = visitor
# 要访问的 xtcp 代理的名字
server_name = p2p_ssh
sk = abcdefg
# 绑定本地端口用于访问 ssh 服务
bind_addr = 127.0.0.1
bind_port = 6000
- 通过 ssh 访问内网机器,假设用户名为 test:
ssh -oPort=6000 test@127.0.0.1
功能说明
配置文件
由于 frp 目前支持的功能和配置项较多,未在文档中列出的功能可以从完整的示例配置文件中发现。
frps 完整配置文件
frpc 完整配置文件
配置文件模版渲染
配置文件支持使用系统环境变量进行模版渲染,模版格式采用 Go 的标准格式。
示例配置如下:
# frpc.ini
[common]
server_addr = {{ .Envs.FRP_SERVER_ADDR }}
server_port = 7000
[ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = {{ .Envs.FRP_SSH_REMOTE_PORT }}
启动 frpc 程序:
export FRP_SERVER_ADDR="x.x.x.x"
export FRP_SSH_REMOTE_PORT="6000"
./frpc -c ./frpc.ini
frpc 会自动使用环境变量渲染配置文件模版,所有环境变量需要以 .Envs 为前缀。
Dashboard
通过浏览器查看 frp 的状态以及代理统计信息展示。
注:Dashboard 尚未针对大量的 proxy 数据展示做优化,如果出现 Dashboard 访问较慢的情况,请不要启用此功能。
需要在 frps.ini 中指定 dashboard 服务使用的端口,即可开启此功能:
[common]
dashboard_port = 7500
# dashboard 用户名密码,默认都为 admin
dashboard_user = admin
dashboard_pwd = admin
打开浏览器通过 http://[server_addr]:7500 访问 dashboard 界面,用户名密码默认为 admin。
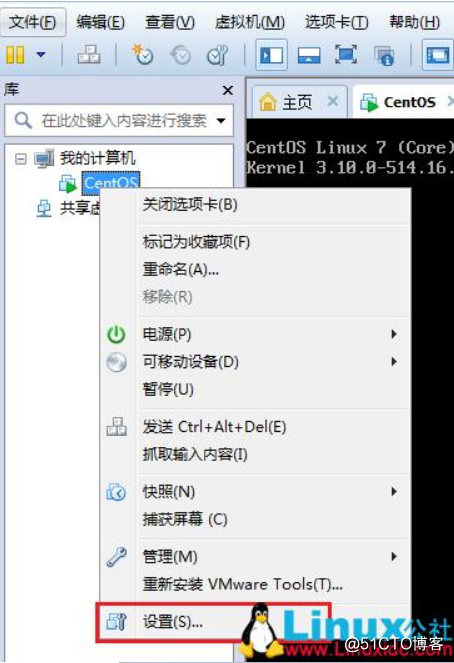
[图片上传失败…(image-1164e2-1562577679203)]
Admin UI
Admin UI 可以帮助用户通过浏览器来查询和管理客户端的 proxy 状态和配置。
需要在 frpc.ini 中指定 admin 服务使用的端口,即可开启此功能:
[common]
admin_addr = 127.0.0.1
admin_port = 7400
admin_user = admin
admin_pwd = admin
打开浏览器通过 http://127.0.0.1:7400 访问 Admin UI,用户名密码默认为 admin。
如果想要在外网环境访问 Admin UI,将 7400 端口映射出去即可,但需要重视安全风险。
身份验证
服务端和客户端的 common 配置中的 token 参数一致则身份验证通过。
加密与压缩
这两个功能默认是不开启的,需要在 frpc.ini 中通过配置来为指定的代理启用加密与压缩的功能,压缩算法使用 snappy:
# frpc.ini
[ssh]
type = tcp
local_port = 22
remote_port = 6000
use_encryption = true
use_compression = true
如果公司内网防火墙对外网访问进行了流量识别与屏蔽,例如禁止了 ssh 协议等,通过设置 use_encryption = true,将 frpc 与 frps 之间的通信内容加密传输,将会有效防止流量被拦截。
如果传输的报文长度较长,通过设置 use_compression = true 对传输内容进行压缩,可以有效减小 frpc 与 frps 之间的网络流量,加快流量转发速度,但是会额外消耗一些 cpu 资源。
TLS
从 v0.25.0 版本开始 frpc 和 frps 之间支持通过 TLS 协议加密传输。通过在 frpc.ini 的 common 中配置 tls_enable = true 来启用此功能,安全性更高。
为了端口复用,frp 建立 TLS 连接的第一个字节为 0x17。
注意: 启用此功能后除 xtcp 外,不需要再设置 use_encryption。
客户端热加载配置文件
当修改了 frpc 中的代理配置,可以通过 frpc reload 命令来动态加载配置文件,通常会在 10 秒内完成代理的更新。
启用此功能需要在 frpc 中启用 admin 端口,用于提供 API 服务。配置如下:
# frpc.ini
[common]
admin_addr = 127.0.0.1
admin_port = 7400
之后执行重启命令:
frpc reload -c ./frpc.ini
等待一段时间后客户端会根据新的配置文件创建、更新、删除代理。
需要注意的是,[common] 中的参数除了 start 外目前无法被修改。
客户端查看代理状态
frpc 支持通过 frpc status -c ./frpc.ini 命令查看代理的状态信息,此功能需要在 frpc 中配置 admin 端口。
端口白名单
为了防止端口被滥用,可以手动指定允许哪些端口被使用,在 frps.ini 中通过 allow_ports 来指定:
# frps.ini
[common]
allow_ports = 2000-3000,3001,3003,4000-50000
allow_ports 可以配置允许使用的某个指定端口或者是一个范围内的所有端口,以 , 分隔,指定的范围以 - 分隔。
端口复用
目前 frps 中的 vhost_http_port 和 vhost_https_port 支持配置成和 bind_port 为同一个端口,frps 会对连接的协议进行分析,之后进行不同的处理。
例如在某些限制较严格的网络环境中,可以将 bind_port 和 vhost_https_port 都设置为 443。
后续会尝试允许多个 proxy 绑定同一个远端端口的不同协议。
TCP 多路复用
从 v0.10.0 版本开始,客户端和服务器端之间的连接支持多路复用,不再需要为每一个用户请求创建一个连接,使连接建立的延迟降低,并且避免了大量文件描述符的占用,使 frp 可以承载更高的并发数。
该功能默认启用,如需关闭,可以在 frps.ini 和 frpc.ini 中配置,该配置项在服务端和客户端必须一致:
# frps.ini 和 frpc.ini 中
[common]
tcp_mux = false
底层通信可选 kcp 协议
底层通信协议支持选择 kcp 协议,在弱网环境下传输效率提升明显,但是会有一些额外的流量消耗。
开启 kcp 协议支持:
- 在 frps.ini 中启用 kcp 协议支持,指定一个 udp 端口用于接收客户端请求:
# frps.ini
[common]
bind_port = 7000
# kcp 绑定的是 udp 端口,可以和 bind_port 一样
kcp_bind_port = 7000
- 在 frpc.ini 指定需要使用的协议类型,目前只支持 tcp 和 kcp。其他代理配置不需要变更:
# frpc.ini
[common]
server_addr = x.x.x.x
# server_port 指定为 frps 的 kcp_bind_port
server_port = 7000
protocol = kcp
- 像之前一样使用 frp,需要注意开放相关机器上的 udp 的端口的访问权限。
连接池
默认情况下,当用户请求建立连接后,frps 才会请求 frpc 主动与后端服务建立一个连接。当为指定的代理启用连接池后,frp 会预先和后端服务建立起指定数量的连接,每次接收到用户请求后,会从连接池中取出一个连接和用户连接关联起来,避免了等待与后端服务建立连接以及 frpc 和 frps 之间传递控制信息的时间。
这一功能比较适合有大量短连接请求时开启。
- 首先可以在 frps.ini 中设置每个代理可以创建的连接池上限,避免大量资源占用,客户端设置超过此配置后会被调整到当前值:
# frps.ini
[common]
max_pool_count = 5
- 在 frpc.ini 中为客户端启用连接池,指定预创建连接的数量:
# frpc.ini
[common]
pool_count = 1
负载均衡
可以将多个相同类型的 proxy 加入到同一个 group 中,从而实现负载均衡的功能。
目前只支持 tcp 类型的 proxy。
# frpc.ini
[test1]
type = tcp
local_port = 8080
remote_port = 80
group = web
group_key = 123
[test2]
type = tcp
local_port = 8081
remote_port = 80
group = web
group_key = 123
用户连接 frps 服务器的 80 端口,frps 会将接收到的用户连接随机分发给其中一个存活的 proxy。这样可以在一台 frpc 机器挂掉后仍然有其他节点能够提供服务。
要求 group_key 相同,做权限验证,且 remote_port 相同。
健康检查
通过给 proxy 加上健康检查的功能,可以在要反向代理的服务出现故障时,将这个服务从 frps 中摘除,搭配负载均衡的功能,可以用来实现高可用的架构,避免服务单点故障。
在每一个 proxy 的配置下加上 health_check_type = {type} 来启用健康检查功能。
type 目前可选 tcp 和 http。
tcp 只要能够建立连接则认为服务正常,http 会发送一个 http 请求,服务需要返回 2xx 的状态码才会被认为正常。
tcp 示例配置如下:
# frpc.ini
[test1]
type = tcp
local_port = 22
remote_port = 6000
# 启用健康检查,类型为 tcp
health_check_type = tcp
# 建立连接超时时间为 3 秒
health_check_timeout_s = 3
# 连续 3 次检查失败,此 proxy 会被摘除
health_check_max_failed = 3
# 每隔 10 秒进行一次健康检查
health_check_interval_s = 10
http 示例配置如下:
# frpc.ini
[web]
type = http
local_ip = 127.0.0.1
local_port = 80
custom_domains = test.yourdomain.com
# 启用健康检查,类型为 http
health_check_type = http
# 健康检查发送 http 请求的 url,后端服务需要返回 2xx 的 http 状态码
health_check_url = /status
health_check_interval_s = 10
health_check_max_failed = 3
health_check_timeout_s = 3
修改 Host Header
通常情况下 frp 不会修改转发的任何数据。但有一些后端服务会根据 http 请求 header 中的 host 字段来展现不同的网站,例如 nginx 的虚拟主机服务,启用 host-header 的修改功能可以动态修改 http 请求中的 host 字段。该功能仅限于 http 类型的代理。
# frpc.ini
[web]
type = http
local_port = 80
custom_domains = test.yourdomain.com
host_header_rewrite = dev.yourdomain.com
原来 http 请求中的 host 字段 test.yourdomain.com 转发到后端服务时会被替换为 dev.yourdomain.com。
设置 HTTP 请求的 header
对于 type = http 的代理,可以设置在转发中动态添加的 header 参数。
# frpc.ini
[web]
type = http
local_port = 80
custom_domains = test.yourdomain.com
host_header_rewrite = dev.yourdomain.com
header_X-From-Where = frp
对于参数配置中所有以 header_ 开头的参数(支持同时配置多个),都会被添加到 http 请求的 header 中,根据如上的配置,会在请求的 header 中加上 X-From-Where: frp。
获取用户真实 IP
HTTP X-Forwarded-For
目前只有 http 类型的代理支持这一功能,可以通过用户请求的 header 中的 X-Forwarded-For 来获取用户真实 IP,默认启用。
Proxy Protocol
frp 支持通过 Proxy Protocol 协议来传递经过 frp 代理的请求的真实 IP,此功能支持所有以 TCP 为底层协议的类型,不支持 UDP。
Proxy Protocol 功能启用后,frpc 在和本地服务建立连接后,会先发送一段 Proxy Protocol 的协议内容给本地服务,本地服务通过解析这一内容可以获得访问用户的真实 IP。所以不仅仅是 HTTP 服务,任何的 TCP 服务,只要支持这一协议,都可以获得用户的真实 IP 地址。
需要注意的是,在代理配置中如果要启用此功能,需要本地的服务能够支持 Proxy Protocol 这一协议,目前 nginx 和 haproxy 都能够很好的支持。
这里以 https 类型为例:
# frpc.ini
[web]
type = https
local_port = 443
custom_domains = test.yourdomain.com
# 目前支持 v1 和 v2 两个版本的 proxy protocol 协议。
proxy_protocol_version = v2
只需要在代理配置中增加一行 proxy_protocol_version = v2 即可开启此功能。
本地的 https 服务可以通过在 nginx 的配置中启用 Proxy Protocol 的解析并将结果设置在 X-Real-IP 这个 Header 中就可以在自己的 Web 服务中通过 X-Real-IP 获取到用户的真实 IP。
通过密码保护你的 web 服务
由于所有客户端共用一个 frps 的 http 服务端口,任何知道你的域名和 url 的人都能访问到你部署在内网的 web 服务,但是在某些场景下需要确保只有限定的用户才能访问。
frp 支持通过 HTTP Basic Auth 来保护你的 web 服务,使用户需要通过用户名和密码才能访问到你的服务。
该功能目前仅限于 http 类型的代理,需要在 frpc 的代理配置中添加用户名和密码的设置。
# frpc.ini
[web]
type = http
local_port = 80
custom_domains = test.yourdomain.com
http_user = abc
http_pwd = abc
通过浏览器访问 http://test.yourdomain.com,需要输入配置的用户名和密码才能访问。
自定义二级域名
在多人同时使用一个 frps 时,通过自定义二级域名的方式来使用会更加方便。
通过在 frps 的配置文件中配置 subdomain_host,就可以启用该特性。之后在 frpc 的 http、https 类型的代理中可以不配置 custom_domains,而是配置一个 subdomain 参数。
只需要将 *.{subdomain_host} 解析到 frps 所在服务器。之后用户可以通过 subdomain 自行指定自己的 web 服务所需要使用的二级域名,通过 {subdomain}.{subdomain_host} 来访问自己的 web 服务。
# frps.ini
[common]
subdomain_host = frps.com
将泛域名 *.frps.com 解析到 frps 所在服务器的 IP 地址。
# frpc.ini
[web]
type = http
local_port = 80
subdomain = test
frps 和 frpc 都启动成功后,通过 test.frps.com 就可以访问到内网的 web 服务。
注:如果 frps 配置了 subdomain_host,则 custom_domains 中不能是属于 subdomain_host 的子域名或者泛域名。
同一个 http 或 https 类型的代理中 custom_domains 和 subdomain 可以同时配置。
URL 路由
frp 支持根据请求的 URL 路径路由转发到不同的后端服务。
通过配置文件中的 locations 字段指定一个或多个 proxy 能够匹配的 URL 前缀(目前仅支持最大前缀匹配,之后会考虑正则匹配)。例如指定 locations = /news,则所有 URL 以 /news 开头的请求都会被转发到这个服务。
# frpc.ini
[web01]
type = http
local_port = 80
custom_domains = web.yourdomain.com
locations = /
[web02]
type = http
local_port = 81
custom_domains = web.yourdomain.com
locations = /news,/about
按照上述的示例配置后,web.yourdomain.com 这个域名下所有以 /news 以及 /about 作为前缀的 URL 请求都会被转发到 web02,其余的请求会被转发到 web01。
通过代理连接 frps
在只能通过代理访问外网的环境内,frpc 支持通过 HTTP PROXY 和 frps 进行通信。
可以通过设置 HTTP_PROXY 系统环境变量或者通过在 frpc 的配置文件中设置 http_proxy 参数来使用此功能。
仅在 protocol = tcp 时生效。
# frpc.ini
[common]
server_addr = x.x.x.x
server_port = 7000
http_proxy = http://user:pwd@192.168.1.128:8080
范围端口映射
在 frpc 的配置文件中可以指定映射多个端口,目前只支持 tcp 和 udp 的类型。
这一功能通过 range: 段落标记来实现,客户端会解析这个标记中的配置,将其拆分成多个 proxy,每一个 proxy 以数字为后缀命名。
例如要映射本地 6000-6005, 6007 这6个端口,主要配置如下:
# frpc.ini
[range:test_tcp]
type = tcp
local_ip = 127.0.0.1
local_port = 6000-6006,6007
remote_port = 6000-6006,6007
实际连接成功后会创建 8 个 proxy,命名为 test_tcp_0, test_tcp_1 ... test_tcp_7。
插件
默认情况下,frpc 只会转发请求到本地 tcp 或 udp 端口。
插件模式是为了在客户端提供更加丰富的功能,目前内置的插件有 unix_domain_socket、http_proxy、socks5、static_file。具体使用方式请查看使用示例。
通过 plugin 指定需要使用的插件,插件的配置参数都以 plugin_ 开头。使用插件后 local_ip 和 local_port 不再需要配置。
使用 http_proxy 插件的示例:
# frpc.ini
[http_proxy]
type = tcp
remote_port = 6000
plugin = http_proxy
plugin_http_user = abc
plugin_http_passwd = abc
plugin_http_user 和 plugin_http_passwd 即为 http_proxy 插件可选的配置参数。
frp安装配置之内网穿透最佳方案
补坑来了,上次写过
cpolar实现免费的内网穿透,但是最大的问题在于免费版不能用自己的域名,毕竟是第三方提供的服务器,免费的都有限制,刚好自己有一台阿里云的云服务器,所以比较完美的方法是用开源的frp自己搭建一个内网穿透服务器,这样就可以用阿里云的公网ip绑定自己的域名了。
或许有人会问,既然已经有了公网服务器为啥还要内网穿透?毕竟公网服务器都比较贵啊,楼主的阿里云服务器一年将近700块,才2g内存,40g存储,如果把想要跑的服务都跑在上面,很快就熬不住了,不如就拿来做内网穿透服务器,就起个转发功能,自己家里买个树莓派,安装linux系统,就可以跑各种东西了,也不用担心存储的问题。Frp是一款流行的跨平台开源免费内网穿透反向代理应用,支持 Windows、macOS与 Linux,支持 TCP、UDP 协议,支持http 和 https 协议,在公网服务器安装一个server端,内网服务器安装一个客户端,起到一个中转转发的作用,从而实现内网暴露到外网,实际就是一个反向代理转发器。
服务器端安装配置 Frp
FRP 使用 Go 语言开发,可以支持 Windows、Linux、macOS、ARM 等多平台部署。FRP 安装非常容易,只需下载对应系统平台的软件包并解压就可用了。这里以 Linux 系统为例:
export FRP_VERSION=0.32.1
sudo mkdir -p /etc/frp
cd /etc/frp
sudo wget "https://github.com/fatedier/frp/releases/download/v${FRP_VERSION}/frp_${FRP_VERSION}_linux_amd64.tar.gz"
sudo tar xzvf frp_${FRP_VERSION}_linux_amd64.tar.gz
sudo mv frp_${FRP_VERSION}_linux_amd64/* /etc/frp
截止写这篇文章为止,github上的最新版本是0.32.1,如果以后出了更新的版本只要改一下上面的版本号就行了,可以去https://github.com/fatedier/frp/查看最新版本信息。
FRP 默认提供了 2 个服务端配置文件,一个是简化版的 frps.ini,另一个是完整版的 frps_full.ini。初学者只需用简版配置即可,在简版 frps.ini 配置文件里,默认设置了监听端口为 7000,可以按需修改它。
需要将服务器的系统防火墙安全组放行,设置 7000 或修改过的对应端口的「允许入站和出站」,否则会一直连接不上的哦!!!这个切记!!
启动 FRP 服务端(非后台启动,未配置开机自启的情况下)
如服务器使用 Win 系统,假设解压到 c:\frp 文件夹,那么只需这样启动:
c:\frp\frps.exe -c c:\frp\frps.exe
当然,这样的启动一般测试可以,生产环境多数为后台启动,需要配置后台运行和开机自启
使用systemctl配置后台运行和开机自启
sudo vim /lib/systemd/system/frps.service
在frps.service里写入以下内容
[Unit]
Description=fraps service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
#启动服务的命令(此处写你的frps的实际安装目录)
ExecStart=/etc/frp/frps -c /etc/frp/frps.ini
[Install]
WantedBy=multi-user.target
启动frps
sudo systemctl start frps
#打开自启动
sudo systemctl enable frps
如果要重启应用,sudo systemctl restart frps
如果要停止应用,sudo systemctl stop frps
如果要查看应用的日志,sudo systemctl status frps
如果启动时7000端口被占用
#查看端口号
netstat -anp|grep 7000
或
或
得到进程id(pid)之后,杀掉进程
至此服务端安装完毕并已经启动
配置frp客户端(内网机器上)
可以将 Frp 客户端安装在内网的 Windows 电脑、Linux 设备 比如树莓派 或者 NAS,甚至部分路由器等设备上。Linux 客户端的安装和启动与服务器端没有太多区别,只是对应运行程序是 frpc 而不是 frps。
如果是linux设置,安装和设置重启过程这里就省略了,和上面一样的,如果是windows电脑,Frp 是绿色程序,下载软件包回来解压后,启动 frpc.exe 即可。
在启动前,我们需要先修改配置文件frpc.ini
比如服务器的公网ip是1.2.3.4.5
[common]
server_addr = 1.2.3.4.5
server_port = 7000
[ssh]
type = tcp
local_ip = 127.0.0.1
local_port = 22
remote_port = 7001
[RDPDEEPIN]
type = tcp
local_ip = 127.0.0.1
local_port = 3389
remote_port = 7002
[RDPWINDOWS]
type = tcp
local_ip = 192.168.0.109
local_port = 3389
remote_port = 7004
[TOMCAT]
type = tcp
local_ip = 127.0.0.1
local_port = 8081
remote_port = 7003
如上,中括号里面的文字是标识,可以自定义,第一个server-port = 7000是服务器上的server端端口。
这里配置了四个应用,分别是
1.ssh远程登录22端口,映射公网的7001;
2.rdp协议的deepin桌面连接3389端口,映射公网的7002;
3.rdp协议的内网ip为192.168.0.109的windows3389端口,映射公网的7004;
4.tomcat应用,8081端口映射公网的7003
以上还可以配置更多端口,上面的7001到7004都要在服务器安全组放行
启动frp客户端
linux和上面写的服务端启动方法一样
windows假设已将 Frp 的客户端解压缩到 c:\frp 目录中,那么启动 Frp 客户端的命令就是:
c:\frp\frpc.exe -c c:\frp\frpc.ini
Linux 启动 Frp 客户端命令(非后台启动,未配置开机自启的情况下):
启动之后看到 “start proxy success”字样就表示启动成功了。
远程访问
公网ip:7001就可以ssh连接到内网的deepin
公网ip:7002就可以rdp连接到内网的deepin桌面
公网ip:7004就可以rdp连接到内网的windows
公网ip或域名:7003就可以访问到内网的tomcat应用
这样真的就完美舒服了。
参考:https://www.iplaysoft.com/frp.html
https://blog.csdn.net/x7418520/article/details/81077652






 此处实际上应该还要卸载,只是我忘记了,大家记得要执行下述命令来进行dnsmasq的卸载
此处实际上应该还要卸载,只是我忘记了,大家记得要执行下述命令来进行dnsmasq的卸载

 根据官方给出的命令,执行就是了
根据官方给出的命令,执行就是了 如果不出意外的话,基本上都能顺利的进入配置界面
如果不出意外的话,基本上都能顺利的进入配置界面











 之后Pi-hole就会基于刚刚的配置开始自动安装,这期间需要下载一些组件,如果网络不好的话就有可能会失败,所以代理还是很有必要的
之后Pi-hole就会基于刚刚的配置开始自动安装,这期间需要下载一些组件,如果网络不好的话就有可能会失败,所以代理还是很有必要的

 接下来就进入最后的一部分配置,包括防火墙,登陆密码等
接下来就进入最后的一部分配置,包括防火墙,登陆密码等



 直接点击
直接点击 这个界面只是状态展示,如果要进行管理,需要登录进去,点击左侧的Login进行登录,密码在Pi-hole安装完之后已经显示在界面上了
这个界面只是状态展示,如果要进行管理,需要登录进去,点击左侧的Login进行登录,密码在Pi-hole安装完之后已经显示在界面上了 如果嫌自动生成的密码太难记,直接可以使用
如果嫌自动生成的密码太难记,直接可以使用 登陆之后所有功能都会在左侧显示,状态界面显示的内容也会更丰富
登陆之后所有功能都会在左侧显示,状态界面显示的内容也会更丰富

 点击右下角的SAVE之后即可生效,同时在
点击右下角的SAVE之后即可生效,同时在
 此时DHCP功能的配置文件名是
此时DHCP功能的配置文件名是
 此处我推荐一个广告过滤规则的Github项目:
此处我推荐一个广告过滤规则的Github项目: 项目提供的几种类型的规则地址,我主要推荐如下两个,这两个任选其一即可,具体的不同可以查看项目的说明
项目提供的几种类型的规则地址,我主要推荐如下两个,这两个任选其一即可,具体的不同可以查看项目的说明 直接复制规则的地址,填入Blocklists选项卡的规则地址位置,点击Save and Update使其生效即可
直接复制规则的地址,填入Blocklists选项卡的规则地址位置,点击Save and Update使其生效即可

 保存并退出,然后执行
保存并退出,然后执行 同样的在Blocklists中填写规则地址,由于
同样的在Blocklists中填写规则地址,由于

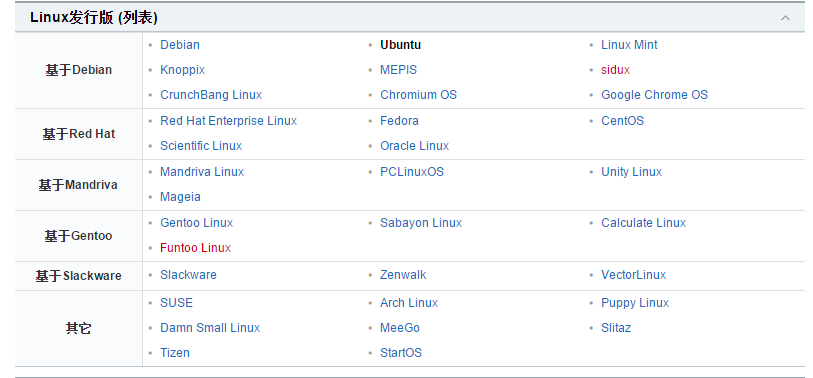
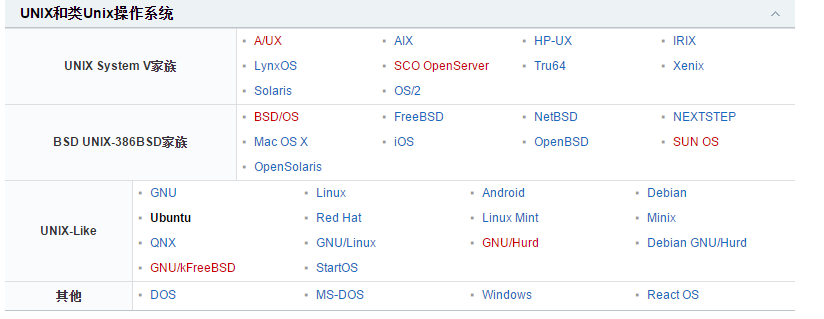
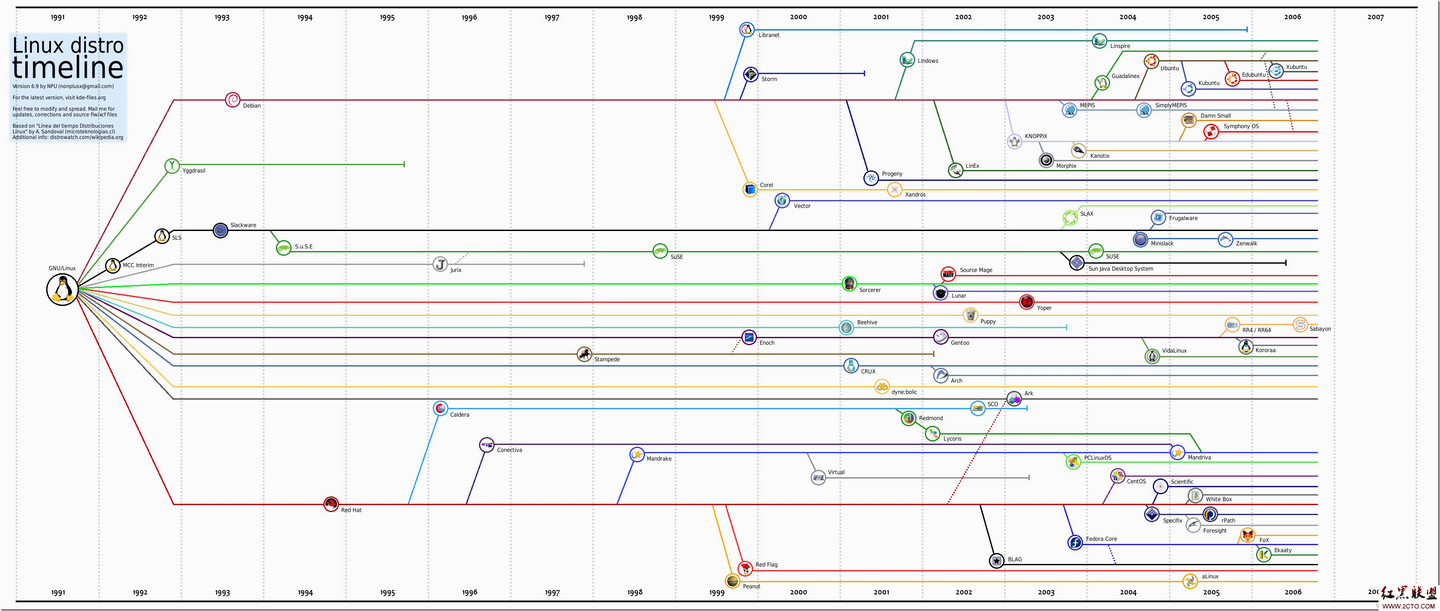
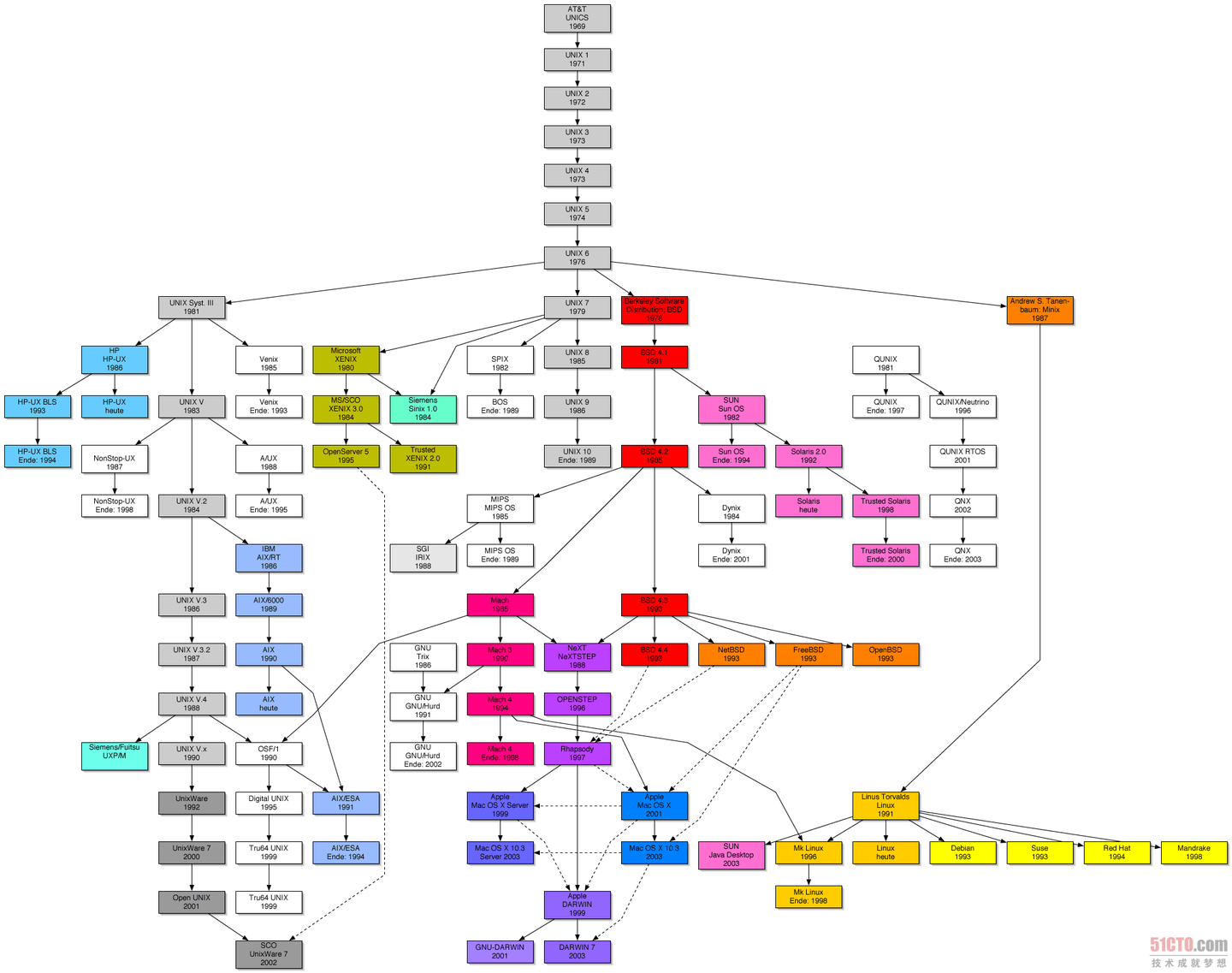
 Linux 命令大全
Linux 命令大全
rapattern
rap***ern@foxmail.com
参考地址
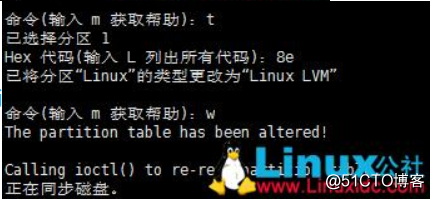
[root@localhost ~]# ls -ahl
total 28K
dr-xr-x—. 2 root root 135 Dec 16 02:34 .
dr-xr-xr-x. 17 root root 224 Dec 14 01:38 ..
-rw——-. 1 root root 1.3K Dec 14 01:38 anaconda-ks.cfg
-rw——-. 1 root root 1.2K Dec 16 02:34 .bash_history
-rw-r–r–. 1 root root 18 Dec 28 2013 .bash_logout
-rw-r–r–. 1 root root 176 Dec 28 2013 .bash_profile
-rw-r–r–. 1 root root 176 Dec 28 2013 .bashrc
-rw-r–r–. 1 root root 100 Dec 28 2013 .cshrc
-rw-r–r–. 1 root root 129 Dec 28 2013 .tcshrc
从上面可以看到,每一行都有7列,分别是:
d表示目录,-表示文件,l表示链接文件,d表示可随机存取的设备,如U盘等,c表示一次性读取设备,如鼠标、键盘等。后9位,依次对应三种身份所拥有的权限,身份顺序为:owner、group、others,权限顺序为:readable、writable、excutable。如:-r-xr-x---的含义为当前文档是一个文件,拥有者可读、可执行,同一个群组下的用户,可读、可执行,其他人没有任何权限。rapattern
rap***ern@foxmail.com
参考地址
12个月前 (01-14)