
robots.txt文件主要用于各个搜索引擎的蜘蛛爬取规则,合理设置robots.txt文件,可以让蜘蛛爬取,和不准许蜘蛛爬取的页面,这样有助于网站的seo
方法/步骤
-
首先打开电脑,依次点击“开始——所有程序——附件——记事本”
-
打开记事本文件
-
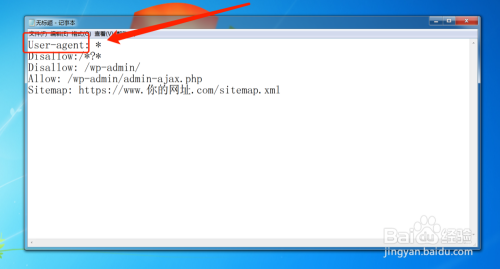
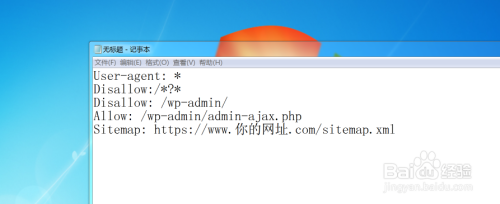
然后输入User-agent,表示“允许”的意思
-
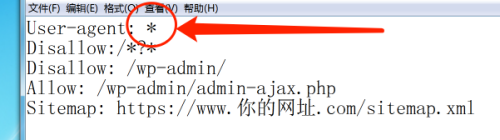
按照这样的写法就可以User-agent: *,其中“*号”表示允许所有的蜘蛛抓取,如果你写的是“User-agent: Baiduspider” ,那么就是只允许百度的蜘蛛来抓取。
-
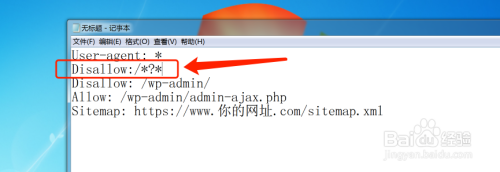
这样写 Disallow:/*?* 禁止抓取动态的页面。这样的好处是,如果你的网址做了伪静态的话,如果不禁止,那么等于蜘蛛重复抓取了你网址的静态页面和动态页面,这样就不利于seo,所以如果你网站做了伪静态一定要禁止蜘蛛抓取动态链接。
-
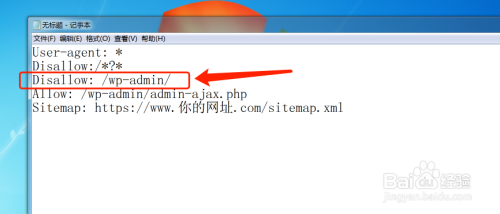
这样写 Disallow: /wp-admin/ 就是禁止蜘蛛抓取 /wp-admin/ 目录,为什么禁止这个目录?这个地址是wordpress默认的后台登录地址,没有必要让蜘蛛抓取,这是属于重复页面(因为每个人的wordpress后台登录界面都一样)。
-
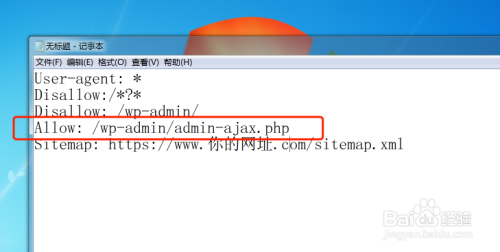
这样写 Allow: /wp-admin/admin-ajax.php 表示允许蜘蛛抓取这个目录的文件
-
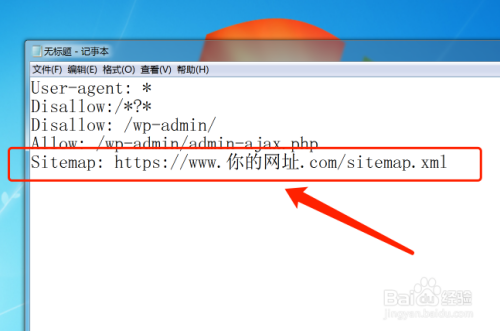
这样写 Sitemap: https://www.你的网址.com/sitemap.xml 让蜘蛛访问你的网站地图
-
然后写完了所有的内容,就是这样的格式。
-
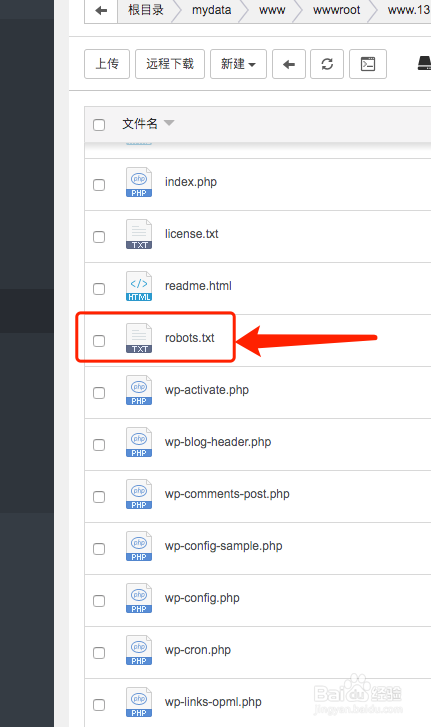
然后保存txt文件,并命名为“robots.txt”

-
然后把robots.txt文件上传到你的网站根目录
-
然后在你的浏览器地址栏目中,输入你的网址,加上/robots.txt就可以成功的访


说到 robots.txt 大家已经都不会陌生了,但是有些时候很多的细节却还是没有被大多数人注意,比如子凡就忽略了一个细节,导致最近的一些文章在搜索引擎结果中出现了重复而没有意义的链接,如果你也是使用的WordPress,不妨你也看看你自己的 robots.txt 文件。
如果你的 WordPress 站点还没有 robots.txt 文件,那么子凡觉得你就更有必要添加一个了,即使你的站点可以让搜索引擎随意抓取,因为搜索引擎机器人访问网站时,首先会寻找站点根目录有没有 robots.txt 文件,如果有这个文件就根据文件的内容确定收录范围,如果没有就按默认访问以及收录所有页面。另外,当搜索蜘蛛发现不存在 robots.txt 文件时,会产生一个 404 错误日志在服务器上,从而增加服务器的负担,因此为站点添加一个 robots.txt 文件还是很重要的。
好了,还是来分享一个经过子凡整理的比较完善的适用于 WordPress 的 robots.txt 文件内容吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
User-agent: * Disallow: /wp-admin/ Disallow: /wp-content/ Disallow: /wp-includes/ Disallow: /trackback/ Disallow: /comments/ Disallow: /attachment/ Disallow: /comments/feed Disallow: /feed Disallow: /*/feed Disallow: /*/comment-page-* Disallow: /*?replytocom=* Disallow: /*/trackback Disallow: /?s=* Disallow: /*/?s=*\ Disallow: /wp-*.php Sitemap: http://yourdomain.com/sitemap.html
使用方法:新建一个名称为 robots.txt 文本文件,将以上的内容放进去,然后上传到网站根目录即可。
最后还是简单的解析一下其对应作用
1、User-agent: *
允许所有搜索引擎抓取网站,除非你网站有特别针对某个或多个搜索引擎,你可以适当的设置其抓取。如下只允许百度和谷歌抓取:
1 2 3 4
User-agent: Baiduspider Disallow: / User-agent: Googlebot Disallow: /
这样设置的意思为只允许百度和谷歌的蜘蛛抓取所有,但是这里子凡用的是 Disallow 并设置的/根目录,所以这里其实是禁止了百度和谷歌抓取,如果要允许所有可以使用Allow,大家可以举一反三的使用,仔细的体会感受一下。
2、Disallow: /wp-admin/、Disallow: /wp-content/和 Disallow: /wp-includes/
用于告诉搜索引擎不要抓取后台程序文件页面。3、Disallow: /*/comment-page-*和 Disallow: /*?replytocom=*
禁止搜索引擎抓取评论分页等相关链接。4、Disallow: /category/*/page/和 Disallow: /tag/*/page/
禁止搜索引擎抓取收录分类和标签的分页。(这一条子凡并未添加到上面演示,因为不同 WordPress 站点可能会有所不同,大家可以根据需要添加)5、Disallow: /*/trackback 和 Disallow: /trackback/
禁止搜索引擎抓取收录 trackback 等垃圾信息6、Disallow: /feed、Disallow: /*/feed 和 Disallow: /comments/feed
禁止搜索引擎抓取收录 feed 链接,feed 只用于订阅本站,与搜索引擎无关。7、Disallow: /?s=*和 Disallow: /*/?s=*\
禁止搜索引擎抓取站内搜索结果8、Disallow: /attachment/
禁止搜索引擎抓取附件页面,比如毫无意义的图片附件页面。9、Disallow: /wp-*.php
禁止搜索引擎抓取 WordPress 网站根目录的以 wp 开头的文件。10、Sitemap: http://yourdomain.com/sitemap.html
这个就是为了方便搜索引擎利用的网站地图,具体的根据自己网站需要添加。robots.txt是搜索引擎爬行网站的控制文件,按照一定的语法告诉搜索引擎哪些网页能爬,哪些不能爬,对于robots.txtd的介绍和书写语法,你可以参考这篇博文:网络蜘蛛访问控制文件robot.txt的写法 。
可能你想说,收录量不是越多越好吗?
其实不然,网站的网页不是收录越多越好,大家都知道搜索引擎比较网络上的网页相似度(相似度太高的两个页面会分散权重)的时候,不仅仅会进行不同网站间的纵向比较,而且会进行同一网站不同页面间的比较,所以,比如对于个人博客的作者归档和首页,页面内容差不多一样,我们完全可以屏蔽蜘蛛访问作者归档的页面。下面我来详细地介绍一下wordpress怎样写robots.txt利于SEO优化。
WordPress怎样写Robots.Txt利于SEO优化
一、屏蔽没有必要收录的一些链接
1、屏蔽捉取站内搜索结果
Disallow: ?s=*
这个就不用解释了,屏蔽捉取站内搜索结果。站内没出现这些链接不代表站外没有,如果收录了会造成和TAG等页面的内容相近。
2、屏蔽Spider捉取程序文件
Disallow: /wp-*/
屏蔽spider捉取程序文件,wp-*表示wp-admin,wp-include等文件夹都不让搜索蜘蛛爬行,这节约了搜索引擎蜘蛛资源。
3、屏蔽Feed
Disallow: /feed/*
Disallow: /*/*/feed/*
Disallow: /*/*/*/feed/*头部代码里的feed链接主要是提示浏览器用户可以订阅本站,而一般的站点都有RSS输出和网站地图,故屏蔽搜索引擎抓取这些链接,相当有必要,应为feed里面的内容基本就是你文章内容的重复,相同内容会让百度降低单页面权重,同时这也节约蜘蛛资源和服务器的压力。
4、屏蔽捉取留言信息链接
Disallow:/*?replytocom*
Disallow: /comments/
Disallow: /*/comments/屏蔽留言信息链接。需要指出的是,屏蔽留言信息链接不是说不让蜘蛛收录你文章的评论页面,而是这样的链接打开后,整个页面就只有一个评论,完全没有被收录的必要,同时也节约蜘蛛资源,故屏蔽之。
5、屏蔽其他的一些链接,避免造成重复内容和隐私问题
Disallow: /date/
Disallow: /author/
Disallow: /category/
Disallow: /?p=*&preview=true
Disallow: /?page_id=*&preview=true
Disallow: /wp-login.php这些屏蔽规则你可以根据自己的需求决定是否创建,屏蔽data、author、category等页面都是为了避免太多重复内容,
6、Disallow: /?P=*
屏蔽捉取短链接。默认头部里的短链接,百度等搜索引擎蜘蛛会试图捉取,虽然最终短链接会301重定向到固定链接,但这样依然造成蜘蛛资源的浪费。
7.屏蔽特定格式
Disallow: /*.js$
Disallow: /*.css$屏蔽对js、css格式文件的抓取,节约蜘蛛资源,降低服务器压力,你可以根据实际要求是否屏蔽你的图片被抓取。
8.其它不想被抓取的页面
Disallow: /*?connect=*
Disallow: /kod/*
Disallow: /api/*- /*?connect=*:我的博客登录链接
- /kod/*:在线文件管理链接
- /api/*:我自制的API链接
二、使用Robots.Txt需要注意的几点地方:
- 1、有独立User-agent的规则,会排除在通配“*”User agent的规则之外;
- 2、指令区分大小写,忽略未知指令,下图是本博客的robots.txt文件在Google管理员工具里的测试结果;
- 3、“#”号后的字符参数会被忽略;
- 4、可以写入sitemap文件的链接,方便搜索引擎蜘蛛爬行整站内容。
- 5、每一行代表一个指令,空白和隔行会被忽略;
- 6、尽量少用Allow指令,因为不同的搜索引擎对不同位置的Allow指令会有不同看待。
上面的这些Disallow指令都不是强制要求的,可以按需写入。也建议站点开通百度站长工具,检查站点的robots.txt是否规范。
三、百度站长工具Robots.Txt工具的使用方法
百度站长工具robots.txt工具网址:http://zhanzhang.baidu.com/robots/index

百度站长工具robots.txt工具的使用方法

















你真的太强悍了!百度做到 pr5了!!学习收藏了!
个人博客做到那么高的权重很不容易呀
签到成功!签到时间:上午9:24:55,每日签到,生活更精彩哦~
强悍,大神不愧为大神
文章写的不错,学习到了很多。
很棒~写的很详细,可以学到很多
学到了 404 可以这样处理
请教 运行脚本提示这个错误是什么意思啊
@猢狲代码贴过去不对吧,要么就是系统兼容性问题,玩网站、玩服务器还是用centos比较好,大部分教程基于centos写的,你这个是debian
写的很详细很不错,404页面在网站中也是很重要的
每一篇博客,都是精品,值得品鉴 😀
宝塔面板生成不了404文件文档,代码如下
补充一下上一句评论:
宝塔面板生成不了404文件文档,
日志格式如下
脚本代码如下