wordpress设置404页面的方法
wordpress是很多新手站长搭建个人博客最喜爱的程序,但是很大新手站长发现在众多模板中很少有404页面,但是404页面是WWW网站访问比较经常出现的错误。最常见的出错提示:404 NOT FOUND。

404页面的目的有两个,其一是为了良好的用户体验;使用户发现错误页面之后可以去网站其他位置继续浏览,比如我们可以在404页面上设置一个网站首页,引导用户继续浏览下去。其二是在搜索引擎发现此网页时,网页需要反馈一个正确的状态码,当搜索引擎蜘蛛在请求某个URL时得到“404”状态回应时,即知道该URL已经失效,便不再索引该网页,并向数据中心反馈将该URL表示的网页从索引数据库中删除。

如果站长的服务器是LINUX系统,那linux系统之下设置404分方法如下:
第一步:在.htaccess文件中加入如下语句:ErrorDocument 404 /404.html
如果需要修改的网站目录下没有.htaccess文件自己建立一个即可
第二步,自己建立一个404.html文件,放到网站的根目录就可以了。
也可以使用其他后缀,只要.htaccess中指定同样的文件就可以,例如404.php,404asp

如果站长的服务是WIN主机的话,那linux系统之下设置404分方法如下:
在你的wordpress中找到wp-content/themes/你使用的模板/404.php
如果没有404.php的话那么我们建立一个404.php.代码如下:
<?php get_header(); ?>
<div id=”container” class=”article”>
<div class=”content”>
<?php _e(‘我勒个去,你找的这个页面现在居然不存在。’, ‘404yemian’); ?>
</div>
<?php get_sidebar(); ?>
</div>
<?php get_footer(); ?>
这样你的wordpress就有了自己的404页面了,站长自己也可以设计有个性的404页面!
 总之,张戈博客这次更换主题基本上没有看到明显的SEO影响,反而出现几个新的关键词。好了,题外话到此结束,下面分享一下从Nginx日志分析并生成能提交到搜索引擎的死链文件的Shell脚本。
总之,张戈博客这次更换主题基本上没有看到明显的SEO影响,反而出现几个新的关键词。好了,题外话到此结束,下面分享一下从Nginx日志分析并生成能提交到搜索引擎的死链文件的Shell脚本。
一、前因后果
今天在看百度站长平台的抓取频次的时候,发现最近抓取次数有所下滑,并且平均响应时间也有所上升,感觉和最近频繁折腾主题以及访问量增加有所关系:
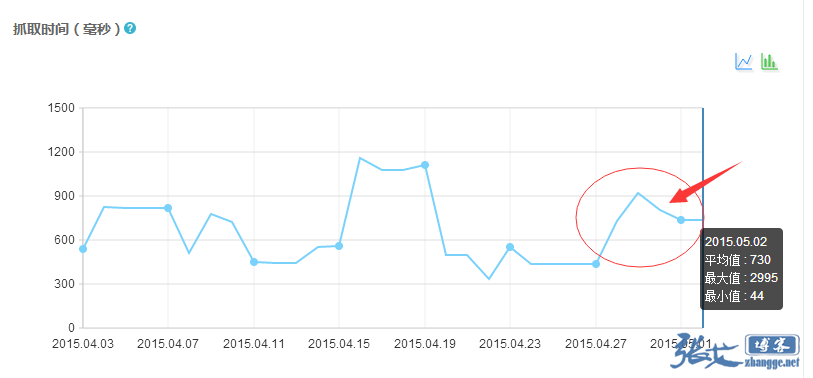
这个问题倒是好解决,等主题稳定了,页面静态缓存文件也就不会频繁被手工删除,整个网站的抓取响应时间应该就能回到正常水平。
再往下看,却发现网站抓取中出现的404数据也呈上升趋势:
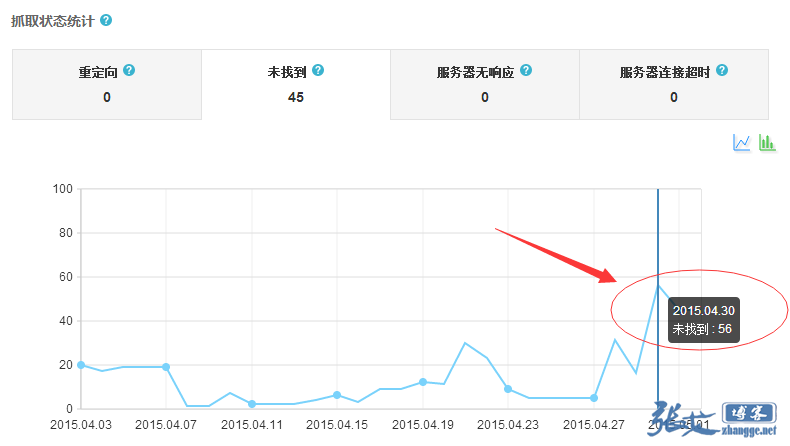
实际上,张戈博客以前是手动提交过死链文件的,但后来没时间也就没去搭理更新了。看来这个工作还得重新做起来,并且实现自动化才行了。
二、Shell脚本
说做就做,简单的写了个 Shell 脚本就搞定了!
脚本名称:网站死链生成脚本
脚本功能:每天定时分析网站前一天的 nginx 日志, 然后提取状态码为404并且UA为百度蜘蛛的抓取路径,并写入到网站根目录下的 death.txt 文件,用于提交百度死链。
脚本代码:
|
|
|
|
#Desc: Death Chain File Script
|
|
|
#Author: ZhangGe
|
|
|
#Blog: https://zhang.ge/5038.html
|
|
|
#Date: 2015-05-03
|
|
|
#初始化变量
|
|
|
#定义蜘蛛UA信息(默认是百度蜘蛛)
|
|
|
UA=‘+http://www.baidu.com/search/spider.html’
|
|
|
DATE=`date +%Y-%m-%d -d “1 day ago”`
|
|
|
#定义日志路径
|
|
|
logfile=/home/wwwlogs/zhang.ge_${DATE}.log
|
|
|
#定义死链文件存放路径
|
|
|
deathfile=/home/wwwroot/zhang.ge/death.txt
|
|
|
#定义网站访问地址
|
|
|
website=https://zhang.ge
|
|
|
#分析日志并保存死链数据
|
|
|
for url in `awk -v str=“${UA}“ ‘$9==”404″ && $15~str {print $7}’ ${logfile}`
|
|
|
do
|
|
|
grep -q “$url“ ${deathfile} || echo ${website}${url} >>${deathfile}
|
|
|
done
|
使用说明:
①、脚本适用于每天都做了日志切割的Nginx,没有做的朋友可以参考博客之前的文章:
②、将代码保存为 shell 脚本,比如 deathlink.sh,然后如下建立任务计划:
|
#执行如下命令编辑任务计划
|
|
|
[root@Mars_Server ~]# crontab -e
|
|
|
#每天凌晨1点执行此脚本(注意脚本的实际路径)
|
|
|
0 1 */1 * * /root/death.sh >/dev/null 2>&1
|
|
|
#按下ESC,然后键入 :wq 保存并退出
|
③、执行后,将在网站根目录生成死链文件:death.txt,可以浏览器访问看看内容,比如:
④、前往立即前往提交这个死链文件即可:

这样一来,系统会每天执行脚本,将昨天的百度蜘蛛爬到的404路径保存到网站根目录下的 death.txt,以备百度死链抓取工具前来抓取。
效果截图:
下面贴上这几天死链抓取(百度定时抓取,无需人工干预)及处理情况,效果还是非常明显的: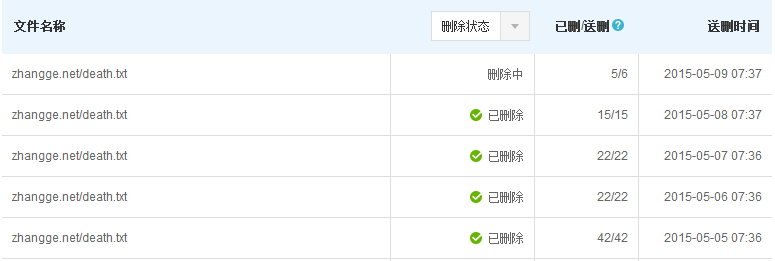
值得说明的是,这些死链记录是累加的,已保存的死链数据,就算百度蜘蛛不爬了也会继续保存,需要人工清理,不过一般不清理也没啥问题。
注意事项:
①、如果你的 nginx服务 并没有配置相应的 access 日志,请自行在 server 下添加所需网站的 access 日志,否则脚本无法使用;
②、脚本适用的access日志格式如下:
|
log_format access ‘$remote_addr – $remote_user [$time_local] “$request” ‘ ‘$status $body_bytes_sent “$http_referer” ‘ ‘”$http_user_agent” $http_x_forwarded_for‘;
|
如果和你的不一样,则需要修改脚本中的awk指定的域(即$9、$15以及$7)。
三、其他拓展
①、如果你之前没有做过 Nginx 日志切割,那么可以直接用下面这个脚本来一次性搞定:
|
|
|
|
#Desc: Cut Nginx Log and Create Death Chain File
|
|
|
#Author: ZhangGe
|
|
|
#Blog: https://zhang.ge/5038.html
|
|
|
#Date: 2015-05-03
|
|
|
#①、初始化变量:
|
|
|
#定义access日志存放路径
|
|
|
LOGS_PATH=/home/wwwlogs
|
|
|
#定义蜘蛛UA信息(默认是百度蜘蛛)
|
|
|
UA=‘+http://www.baidu.com/search/spider.html’
|
|
|
DOMAIN=zhang.ge
|
|
|
#定义前一天日期
|
|
|
DATE=`date +%Y-%m-%d -d “1 day ago”`
|
|
|
#定义日志路径
|
|
|
logfile=/home/wwwlogs/zhang.ge_${DATE}.log
|
|
|
#定义死链文件存放路径
|
|
|
deathfile=/home/wwwroot/zhang.ge/death.txt
|
|
|
#定义网站访问地址
|
|
|
website=https://zhang.ge
|
|
|
#②、Nginx日志切割
|
|
|
mv ${LOGS_PATH}/${DOMAIN}.log ${LOGS_PATH}/${DOMAIN}_${DATE}.log
|
|
|
kill -USR1 `ps axu | grep “nginx: master process” | grep -v grep | awk ‘{print $2}’`
|
|
|
#可选功能: 自动删除30天之前的日志,可自行修改保存时长。
|
|
|
cd ${LOGS_PATH}
|
|
|
find . -mtime +30 -name “*20[1-9][3-9]*” | xargs rm -f
|
|
|
#③、网站死链生成(百度专用)
|
|
|
#分析日志并保存死链数据
|
|
|
for url in `awk -v str=“${UA}“ ‘$9==”404″ && $15~str {print $7}’ ${logfile}`
|
|
|
do
|
|
|
grep -q “$url“ ${deathfile} || echo ${website}${url} >>${deathfile}
|
|
|
done
|
②、其他WEB服务器,比如 Apache 或 IIS,只要参考脚本思路,修改成实际的路径或日志字段,同样可以写一个相同功能的 Shell 或 Batch 脚本,有需求的朋友自己去研究折腾吧!
好了,本文暂时就分享这么多,希望对你有所帮助!
你真的太强悍了!百度做到 pr5了!!学习收藏了!
个人博客做到那么高的权重很不容易呀
签到成功!签到时间:上午9:24:55,每日签到,生活更精彩哦~
强悍,大神不愧为大神
文章写的不错,学习到了很多。
很棒~写的很详细,可以学到很多
学到了 404 可以这样处理
请教 运行脚本提示这个错误是什么意思啊
@猢狲代码贴过去不对吧,要么就是系统兼容性问题,玩网站、玩服务器还是用centos比较好,大部分教程基于centos写的,你这个是debian
写的很详细很不错,404页面在网站中也是很重要的
每一篇博客,都是精品,值得品鉴 😀
宝塔面板生成不了404文件文档,代码如下
补充一下上一句评论:
宝塔面板生成不了404文件文档,
日志格式如下
脚本代码如下