1.主要有两种方式:
like与SQL通配符 和 正则表达式模糊查询。
2.like与SQL ,必须使用like关键字
- SQL的通配符如下:
% 百分号: 替代一个或者多个字符
_ 下划线:仅替代一个字符
[字符列] :字符列中任何一个单一字符
[^字符列] 或者[!字符列]: 不在字符列中的任何一个单一字符
- 用法如下
select 字段列表 from 表名 where 字段 like ‘Ne%’; 表示:查询以Ne开头的数据
select 字段列表 from 表名 where 字段 like ‘%Ne%’; 表示:查询含有Ne的数据
select 字段列表 from 表名 where 字段 like ‘L_ve’; 表示:查询含有 L+某一个字符+ve的数据
select 字段列表 from 表名 where 字段 like ’[abc]%’; 表示:查询a/b/c开头的数据
3.正则表达式模糊查询 必须使用regexp关键字
- 常用元字符,参考我的另一篇文章有列举:https://blog.csdn.net/hernofogot/article/details/83997041
牢记如下规则:
点 . , 尖角符 ^ , 美元符 $ , 字符集 [ ] , 逻辑或 | , 星号 * , 加号 + , 问号 ?,大括号 { }
- 语法如下:
select 字段列表 from 表名 where 字段 [not] regexp [binary] ‘正则表达式’;
- 用法如下:
select 字段列表 from 表名 where 字段 regexp ‘j.’ ; 表示:查询 j 开头且为两个字符的数据
select 字段列表 from 表名 where 字段 regexp ‘158[0-9]{9}’; 表示:查询 158开头,11位的电话号码
。。。。。。
三、总结
- 正则表达式的模式匹配比like 运算符的模式匹配更加强大、灵活。
1,%:表示任意0个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘%三%’
将会把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。
另外,如果需要找出u_name中既有“三”又有“猫”的记录,请使用and条件
SELECT * FROM [user] WHERE u_name LIKE ‘%三%’ AND u_name LIKE ‘%猫%’
若使用 SELECT * FROM [user] WHERE u_name LIKE ‘%三%猫%’
虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
2,_: 表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句:
比如 SELECT * FROM [user] WHERE u_name LIKE ‘_三_’
只找出“唐三藏”这样u_name为三个字且中间一个字是“三”的;
再比如 SELECT * FROM [user] WHERE u_name LIKE ‘三__’; 只找出“三脚猫”这样name为三个字且第一个字是“三”的;
3,[ ]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘[张李王]三’ 将找出“张三”、“李三”、“王三”(而不是“张李王三”);
如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”
SELECT * FROM [user] WHERE u_name LIKE ‘老[1-9]’ 将找出“老1”、“老2”、……、“老9”;
4,[^ ] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘[^张李王]三’ 将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
SELECT * FROM [user] WHERE u_name LIKE ‘老[^1-4]’; 将排除“老1”到“老4”,寻找“老5”、“老6”、……
5,查询内容包含通配符时
由于通配符的缘故,导致我们查询特殊字符“%”、“_”、“[”的语句无法正常实现,而把特殊字符用“[ ]”括起便可正常查询。据此我们写出以下函数:
function sqlencode(str) str=replace(str,”‘;”,”‘;’;”)
str=replace(str,”[“,”[[]”) ‘;此句一定要在最先 str=replace(str,”_”,”[_]”) str=replace(str,”%”,”[%]”) sqlencode=str end function
Mysql模糊查询正常情况下在数据量小的时候,速度还是可以的,但是不容易看出查询的效率,在数据量达到百万级,千万级的甚至亿级时 mysql查询的效率是很关键的,也是很重要的。
一、一般情况下 like 模糊查询的写法:前后模糊匹配
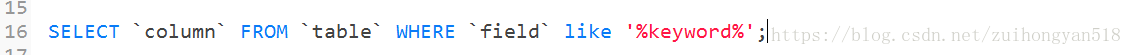
这个SQL语句,如果用explain解释的话,我们很容易就能发觉它是没有走索引搜索,而是对全表进行了扫描,这显然是很慢的,还有卡库的可能。
如果将上面的SQL语句改成下面的写法:

有时候,我们在做模糊查询的时候,并非要想查询的关键词都在开头,所以如果不是特别的要求,”keywork%”并不合适所有的模糊查询。
二、模糊查询高效的方法:
1、LOCATE(’substr’,str,pos)方法
解释:返回 substr 在 str 中第一次出现的位置,如果 substr 在 str 中不存在,返回值为 0 。如果pos存在,返回 substr 在 str 第pos个位置后第一次出现的位置,如果 substr 在 str 中不存在,返回值为0。

实例:

备注:keyword是要搜索的内容,business为被匹配的字段,查询出所有存在keyword的数据
2、POSITION(‘substr’ IN `field`)方法
其实我们就可以把这个方法当做是locate()方法的别名,因为它和locate()方法的作用是一样的。
实例:

3、INSTR(`str`,’substr’)方法
格式:
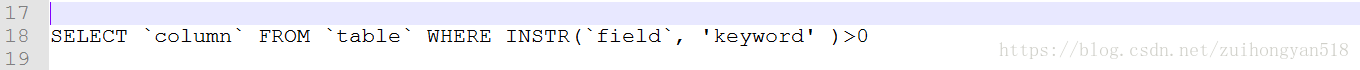
实例:

除了上述的方法外,还有一个函数FIND_IN_SET,这个方法比较特殊,他所查询的必须要是以“,”分隔开。
4、FIND_IN_SET(str1,str2):
返回str2中str1所在的位置索引,其中str2必须以”,”分割开。
格式:
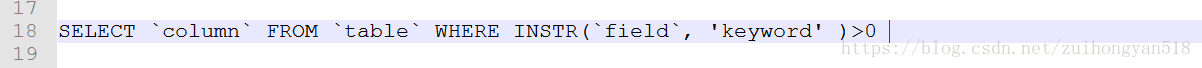
实例:

