~$ #cp -r <源目录> <新目录>
~$ cp -r workspace/project workspace/Cpp
12
但是, 如果我们需要拷贝的文件所在的目录里包含了其他项目或程序的文件或目录, 那我们就不能这么干
比如,
-
在 /etc或者/usr/local/bin下面有很多我们自己项目的相关配置文件和程序文件, 并且我们知道这些文件路径
-
包含指定字符串的文件名, 比如 *.log
-
我们自己制作或者我们比较感兴趣的其他厂商的 *.deb程序包(Ubuntu使用软件包)
针对自己的项目配置文件
我们可以新建一个文本文档, 里面把我们所关心的文件列出来
list.txt
/etc/app/app.cnf
/etc/app/conf.d/a.cnf
/etc/app/conf.d/b.cnf
/etc/app/conf.d/c.cnf
/etc/app/conf.d/d.cnf
12345
这样我们就可以通过使用 cat list.txt 获取到我们的文件路径列表
此时我们只需要使用
~$ cp --parent $(cat list.txt) .
1
就可以将列表里面的所有文件按照原有的目录树结构拷贝到当前目录(或者使用其他目录)
针对包含指定字符串的文件名我们可以用 find 命令获取到文件列表
~$ find /opt/ros/ -name *.a
/opt/ros/kinetic/lib/liboctomath.a
/opt/ros/kinetic/lib/libcsm-static.a
/opt/ros/kinetic/lib/liboptions.a
/opt/ros/kinetic/lib/libegsl.a
/opt/ros/kinetic/lib/liboctomap.a
~$
1234567
然后, 嘿嘿
~$ cp --parent $(find /opt/ros -name *.a) .
1
这不就都按照源目录结构拷贝到当前目录了嘛
针对.deb包的文件列表, 我们也有命令可以获取到路径列表
~$ dpkg -L mysql-server-5.7
/etc
/etc/mysql
/etc/mysql/mysql.conf.d
/etc/mysql/mysql.conf.d/mysqld_safe_syslog.cnf
/etc/mysql/mysql.conf.d/mysqld.cnf
/etc/mysql/debian-start
/etc/mysql/mysql.cnf
/etc/apparmor.d
/etc/apparmor.d/usr.sbin.mysqld
/etc/logrotate.d
/etc/logrotate.d/mysql-server
/etc/init.d
/etc/init.d/mysql
/etc/logcheck
/etc/logcheck/ignore.d.server
/etc/logcheck/ignore.d.server/mysql-server-5_7
/etc/logcheck/ignore.d.workstation
/etc/logcheck/ignore.d.workstation/mysql-server-5_7
/etc/logcheck/ignore.d.paranoid
/etc/logcheck/ignore.d.paranoid/mysql-server-5_7
/etc/init
/etc/init/mysql.conf
~$
123456789101112131415161718192021222324
linux复制指定目录下的全部文件到另一个目录中
复制指定目录下的全部文件到另一个目录中
文件及目录的复制是经常要用到的。linux下进行复制的命令为cp。
假设复制源目录 为 dir1 ,目标目录为dir2。怎样才能将dir1下所有文件复制到dir2下了
如果dir2目录不存在,则可以直接使用
cp -r dir1 dir2
即可。
如果dir2目录已存在,则需要使用
cp -r dir1/. dir2
如果这时使用cp -r dir1 dir2,则也会将dir1目录复制到dir2中,明显不符合要求。
ps:dir1、dir2改成对应的目录路径即可。
cp -r /home/www/xxx/statics/. /home/www/statics
如果存在文件需要先删除
rm -rf /home/www/statics/*
否则会一个个文件提示你确认,使用cp -rf 也一样提示
————————————–
linux下cp整个文件夹的文件到另一个文件夹
cp -ri A/B/* A1/B1/ 回车
若复制过程中询问是否覆盖,输入y按回车,若不想看到提示直接覆盖使用-rf
另外若A A1不在同一目录下,最好填绝对路径,就是/xxx/xxx/A/B/* /xxx/A1/B1/
实例:
cp -ri /home/server/tomcat/* /home/server/test/
cp: target `/home/server/test/’ is not a directory
需要先创建目标文件夹
mkdir /home/server/test
————————————–
copy命令的功能是将给出的文件或目录拷贝到另一文件或目录中,同MSDOS下的copy命令一样,功能十分强大。
语法: cp [选项] 源文件或目录 目标文件或目录
说明:该命令把指定的源文件复制到目标文件或把多个源文件复制到目标目录中。
该命令的各选项含义如下:
– a 该选项通常在拷贝目录时使用。它保留链接、文件属性,并递归地拷贝目录,其作用等于dpR选项的组合。
– d 拷贝时保留链接。
– f 删除已经存在的目标文件而不提示。
– i 和f选项相反,在覆盖目标文件之前将给出提示要求用户确认。回答y时目标文件将被覆盖,是交互式拷贝。
– p 此时cp除复制源文件的内容外,还将把其修改时间和访问权限也复制到新文件中。
– r 若给出的源文件是一目录文件,此时cp将递归复制该目录下所有的子目录和文件。此时目标文件必须为一个目录名。
– l 不作拷贝,只是链接文件。
需要说明的是,为防止用户在不经意的情况下用cp命令破坏另一个文件,如用户指定的目标文件名已存在,用cp命令拷贝文件后,这个文件就会被新源文件覆盖,因此,建议用户在使用cp命令拷贝文件时,最好使用i选项。
例1
复制指定目录下的全部文件到另一个目录中
文件及目录的复制是经常要用到的。linux下进行复制的命令为cp。
假设复制源目录 为 dir1 ,目标目录为dir2。怎样才能将dir1下所有文件复制到dir2下了
如果dir2目录不存在,则可以直接使用
cp -r dir1 dir2
即可。
如果dir2目录已存在,则需要使用
cp -r dir1/. dir2
如果这时使用cp -r dir1 dir2,则也会将dir1目录复制到dir2中,明显不符合要求。
ps:dir1、dir2改成对应的目录路径即可。
例2
复制指定文件到指定文件夹
首先建立一个用于测试的目录,用’tree’命令查看
可见,目录中主要包含用于测试的*.txt文件和用于充当炮灰的*。tes文件
目标是保持当前的目录结构,只把txt文件复制出来
方法一:当不需要的文件类型较为单一时,可以通过完全复制然后删除指定类型的文件完成
Step1 使用命令 cp -r test/ test2 将测试目录test下所有内容完全复制到test2
Step2 组合使用find及xargs,将*.tes文件删除
xargs是给命令传递参数的一个过滤器,可以将前一个命令产生的输出作为后一个命令的参数
命令find test2/ -name ‘*.tes’ |xargs rm -rf, 即将find产生的输出(test2目录下的所有tes文件),作为rm的参数,从而完全删除
适用场景举例:把项目文件备份,要去除其中的.svn文件,可以采用这种方式
方法二:需要的文件为单一类型,带目录结构复制
这种情况下可以使用tar命令将指定类型的文件打包,然后解包,同样需要组合使用find和xargs
Step1 建立目录test3
mkdir test3
Step2 将指定类型文件带目录结构打包
find test/ -name ‘*.txt’ |xargs tar czf test3.tgz
Step3 解包到目录test3
tar zxvf test3.tgz -C test3
适用场景:较为普遍,例如可以复制某个Web项目的所有html/jsp/php文件;或复制其他项目中特定类型的源文件
一、方法
列表:frp.txt
目录: /home/dir
在文件前加入cp
sed “s/^/cp /g” frp.txt >frp2.txt
在文件后加入 /home/dir
sed ‘s/$/& \/home\/dir/g’ frp2.txt> frp3.txt
以上全并成一个:
sed ‘/./{s/^/cp /;s/$/& \/home\/dir/}’ frp.txt > frp4.txt
二、方法
cp $(cat frp.txt) /home/dir
OR
cp `cat frp.txt` /home/dir
find / -name ‘frp*’ |xargs tar czf frp-dir.tgz
cp –parent $(cat list.txt) .

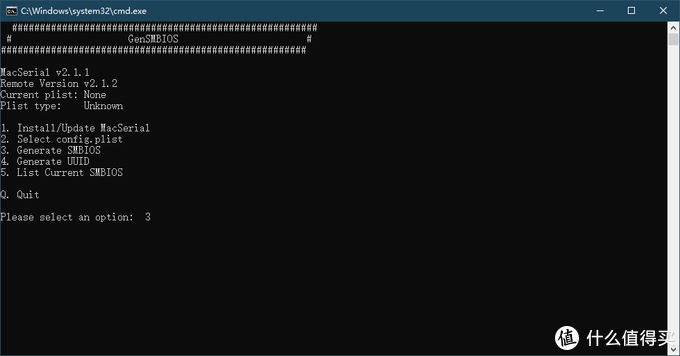
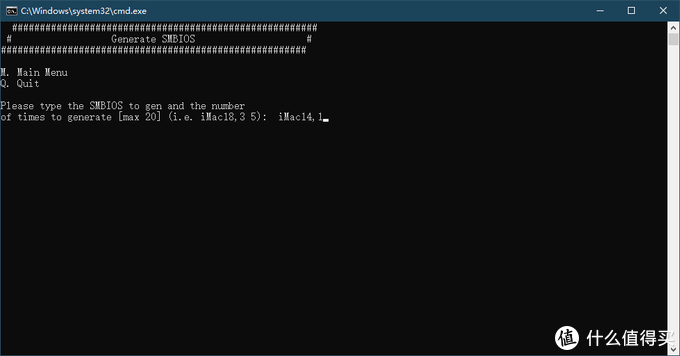
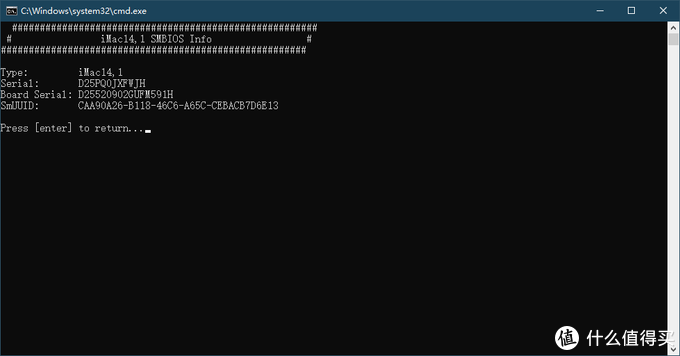






 在linux中scp命令与cp命令一样的是复制文件,下面小编来给各位同学介绍一下关于linux中scp命令使用技巧详
在linux中scp命令与cp命令一样的是复制文件,下面小编来给各位同学介绍一下关于linux中scp命令使用技巧详