1.Ubuntu下安装Nginx比较简单
敲入下列命令即可:
sudo apt-get update
sudo apt-get install nginx
2.Ubuntu下卸载,稍不注意就会入坑

sudo apt-get remove nginx nginx-common # 卸载删除除了配置文件以外的所有文件。
sudo apt-get purge nginx nginx-common # 卸载所有东东,包括删除配置文件。
sudo apt-get autoremove # 在上面命令结束后执行,主要是卸载删除Nginx的不再被使用的依赖包。
sudo apt-get remove nginx-full nginx-common #卸载删除两个主要的包。
sudo service nginx restart #重启nginx
上面的命令基本上都能解决你在Ubuntu下安装卸载Nginx的问题。
3.查看nginx进程
ps aux|grep nginx 在虚拟环境下安装uwsgi pip install uwsgi
######启动Nginx服务
[root@typecodes ~]# service nginx start
######停止Nginx服务
[root@typecodes ~]# service nginx stop
######重启Nginx服务
[root@typecodes ~]# service nginx restart
######Nginx服务的状态
[root@typecodes ~]# service nginx status
######在Nginx服务启动的状态下,重新加载nginx.conf这个配置文件
[root@typecodes ~]# service nginx reload
Django的部署可以有很多方式,采用nginx+uwsgi的方式是其中比较常见的一种方式。
在这种方式中,我们的通常做法是,将nginx作为服务器最前端,它将接收WEB的所有请求,统一管理请求。nginx把所有静态请求自己来处理(这是NGINX的强项)。然后,NGINX将所有非静态请求通过uwsgi传递给Django,由Django来进行处理,从而完成一次WEB请求。
可见,uwsgi的作用就类似一个桥接器。起到桥梁的作用。
Linux的强项是用来做服务器,所以,下面的整个部署过程我们选择在Ubuntu下完成。
一、安装Nginx
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好。
Nginx同样为当前非常流行的web服务器。利用其部署Django,我们在此也做简单的介绍。
Nginx官网:http://nginx.org/
打开ubuntu控制台(ctrl+alt+t)利用Ubuntu的仓库安装。
fnngj@ubuntu:~$ sudo apt-get install nginx #安装
启动Nginx:
fnngj@ubuntu:~$ /etc/init.d/nginx start #启动 fnngj@ubuntu:~$ /etc/init.d/nginx stop #关闭 fnngj@ubuntu:~$ /etc/init.d/nginx restart #重启
修改Nginx默认端口号,打开/etc/nginx/nginx.conf 文件,修改端口号。
server {
listen 8088; # 修改端口号
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
大概在文件36行的位置,将默认的80端口号改成其它端口号,如 8088。因为默认的80端口号很容易被其它应用程序占用。
然后,通过上面命令重启nginx。访问:http://127.0.0.1:8088/
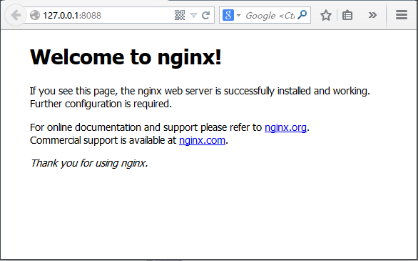
如果出现如上图,说明Nginx启动成功。
二、安装uwsgi
通过pip安装uwsgi。
root@ubuntu:/etc# python3 -m pip install uwsgi
测试uwsgi,创建test.py文件:
def application(env, start_response):
start_response('200 OK', [('Content-Type','text/html')])
return [b"Hello World"]
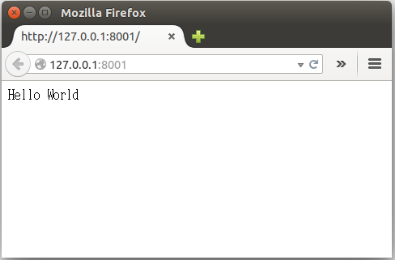
通过uwsgi运行该文件。
fnngj@ubuntu:~/pydj$ uwsgi --http :8001 --wsgi-file test.py
接下来配置Django与uwsgi连接。此处,假定的我的django项目位置为:/home/fnngj/pydj/myweb
fnngj@ubuntu:~/pydj$ uwsgi --http :8001 --chdir /home/fnngj/pydj/myweb/ --wsgi-file myweb/wsgi.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191
常用选项:
http : 协议类型和端口号
processes : 开启的进程数量
workers : 开启的进程数量,等同于processes(官网的说法是spawn the specified number ofworkers / processes)
chdir : 指定运行目录(chdir to specified directory before apps loading)
wsgi-file : 载入wsgi-file(load .wsgi file)
stats : 在指定的地址上,开启状态服务(enable the stats server on the specified address)
threads : 运行线程。由于GIL的存在,我觉得这个真心没啥用。(run each worker in prethreaded mode with the specified number of threads)
master : 允许主进程存在(enable master process)
daemonize : 使进程在后台运行,并将日志打到指定的日志文件或者udp服务器(daemonize uWSGI)。实际上最常用的,还是把运行记录输出到一个本地文件上。
pidfile : 指定pid文件的位置,记录主进程的pid号。
vacuum : 当服务器退出的时候自动清理环境,删除unix socket文件和pid文件(try to remove all of the generated file/sockets)
三、Nginx+uwsgi+Django
接下来,我们要将三者结合起来。首先罗列一下项目的所需要的文件:
myweb/
├── manage.py
├── myweb/
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── myweb_uwsgi.ini
在我们通过Django创建myweb项目时,在子目录myweb下已经帮我们生成的 wsgi.py文件。所以,我们只需要再创建myweb_uwsgi.ini配置文件即可,当然,uwsgi支持多种类型的配置文件,如xml,ini等。此处,使用ini类型的配置。
# myweb_uwsgi.ini file [uwsgi] # Django-related settings socket = :8000 # the base directory (full path) chdir = /home/fnngj/pydj/myweb # Django s wsgi file module = myweb.wsgi # process-related settings # master master = true # maximum number of worker processes processes = 4 # ... with appropriate permissions - may be needed # chmod-socket = 664 # clear environment on exit vacuum = true
这个配置,其实就相当于在上一小节中通过wsgi命令,后面跟一堆参数的方式,给文件化了。
socket 指定项目执行的端口号。
chdir 指定项目的目录。
module myweb.wsgi ,可以这么来理解,对于myweb_uwsgi.ini文件来说,与它的平级的有一个myweb目录,这个目录下有一个wsgi.py文件。
其它几个参数,可以参考上一小节中参数的介绍。
接下来,切换到myweb项目目录下,通过uwsgi命令读取myweb_uwsgi.ini文件启动项目。
fnngj@ubuntu:~$ cd /home/fnngj/pydj/myweb/ fnngj@ubuntu:~/pydj/myweb$ uwsgi --ini myweb_uwsgi.ini [uWSGI] getting INI configuration from myweb_uwsgi.ini *** Starting uWSGI 2.0.12 (32bit) on [Sat Mar 12 13:05:06 2016] *** compiled with version: 4.8.4 on 26 January 2016 06:14:41 os: Linux-3.19.0-25-generic #26~14.04.1-Ubuntu SMP Fri Jul 24 21:18:00 UTC 2015 nodename: ubuntu machine: i686 clock source: unix detected number of CPU cores: 2 current working directory: /home/fnngj/pydj/myweb detected binary path: /usr/local/bin/uwsgi !!! no internal routing support, rebuild with pcre support !!! chdir() to /home/fnngj/pydj/myweb your processes number limit is 15962 your memory page size is 4096 bytes detected max file descriptor number: 1024 lock engine: pthread robust mutexes thunder lock: disabled (you can enable it with --thunder-lock) uwsgi socket 0 bound to TCP address :8000 fd 3 Python version: 3.4.3 (default, Oct 14 2015, 20:37:06) [GCC 4.8.4] *** Python threads support is disabled. You can enable it with --enable-threads *** Python main interpreter initialized at 0x8b52dc0 your server socket listen backlog is limited to 100 connections your mercy for graceful operations on workers is 60 seconds mapped 319920 bytes (312 KB) for 4 cores *** Operational MODE: preforking *** WSGI app 0 (mountpoint='') ready in 1 seconds on interpreter 0x8b52dc0 pid: 7158 (default app) *** uWSGI is running in multiple interpreter mode *** spawned uWSGI master process (pid: 7158) spawned uWSGI worker 1 (pid: 7160, cores: 1) spawned uWSGI worker 2 (pid: 7161, cores: 1) spawned uWSGI worker 3 (pid: 7162, cores: 1) spawned uWSGI worker 4 (pid: 7163, cores: 1)
注意查看uwsgi的启动信息,如果有错,就要检查配置文件的参数是否设置有误。
再接下来要做的就是修改nginx.conf配置文件。打开/etc/nginx/nginx.conf文件,添加如下内容。
……
server {
listen 8099;
server_name 127.0.0.1
charset UTF-8;
access_log /var/log/nginx/myweb_access.log;
error_log /var/log/nginx/myweb_error.log;
client_max_body_size 75M;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:8000;
uwsgi_read_timeout 2;
}
location /static {
expires 30d;
autoindex on;
add_header Cache-Control private;
alias /home/fnngj/pydj/myweb/static/;
}
}
……
listen 指定的是nginx代理uwsgi对外的端口号。
server_name 网上大多资料都是设置的一个网址(例,www.example.com),我这里如果设置成网址无法访问,所以,指定的到了本机默认ip。
在进行配置的时候,我有个问题一直想不通。nginx到底是如何uwsgi产生关联。现在看来大概最主要的就是这两行配置。
include uwsgi_params;
uwsgi_pass 127.0.0.1:8000;
include 必须指定为uwsgi_params;而uwsgi_pass指的本机IP的端口与myweb_uwsgi.ini配置文件中的必须一直。
现在重新启动nginx,翻看上面重启动nginx的命令。然后,访问:http://127.0.0.1:8099/
通过这个IP和端口号的指向,请求应该是先到nginx的。如果你在页面上执行一些请求,就会看到,这些请求最终会转到uwsgi来处理。
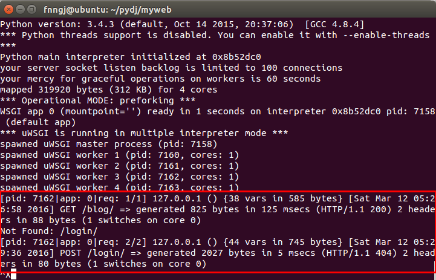
=============
ps: 这个过程本应不算复杂,之前花两天时间没搞定,索性放到了一边,这次又花了两天时间才算搞定。网上搜到的文章比较乱,有些太简单的看不懂,有些又太啰嗦的不知道核心的几步是什么,希望本文能帮到你。