 Linux 命令大全
Linux 命令大全
1.1 为什么需要xargs
管道实现的是将前面的stdout作为后面的stdin,但是有些命令不接受管道的传递方式,最常见的就是ls命令。有些时候命令希望管道传递的是参数,但是直接用管道有时无法传递到命令的参数位,这时候需要xargs,xargs实现的是将管道传输过来的stdin进行处理然后传递到命令的参数位上。也就是说xargs完成了两个行为:处理管道传输过来的stdin;将处理后的传递到正确的位置上。
可以试试运行下面的几条命令,应该能很好理解xargs的作用了:
[root@xuexi tmp]# echo “/etc/inittab” | cat # 直接将标准输入的内容传递给cat
[root@xuexi tmp]# echo “/etc/inittab” | xargs cat # 将标准输入的内容经过xargs处理后传递给cat[root@xuexi tmp]# find /etc -maxdepth 1 -name “*.conf” -print0 | xargs -0 -i grep “hostname” -l {} # 将搜索的文件传递给grep的参数位进行搜索,若不使用xargs,则grep将报错
xargs的作用不仅仅限于简单的stdin传递到命令的参数位,它还可以将stdin或者文件stdin分割成批,每个批中有很多分割片段,然后将这些片段按批交给xargs后面的命令进行处理。
通俗的讲就是原来只能一个一个传递,分批可以实现10个10个传递,每传递一次,xargs后面的命令处理这10个中的每一个,处理完了处理下一个传递过来的批,如下图。
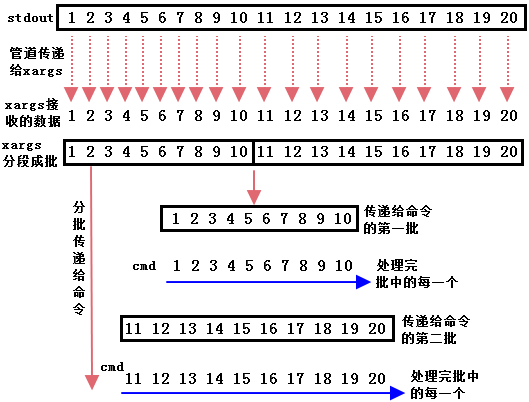
但是应该注意的是,尽管实现了分批处理,但是默认情况下并没有提高任何效率,因为分批传递之后还是一次执行一个。而且有时候分批传递后是作为一个参数的整体,并不会将分批中的信息分段执行。这样看来,实现分批传递的目的仅仅是为了解决一些问题。但事实上,xargs提供了“-P”选项,用于指定并行执行的数量(默认只有一个处理进程,不会提升效率,可以指定为N个子进程,或者指定为0表示尽可能多地利用CPU),这样就能让分批操作更好地利用多核cpu,从而提升效率。例如上面分成了两批,指定”-P 2″可以并发执行这两个批,而非执行完第一批再执行第二批。关于并行处理的详细内容,见后文:高速并行处理之:xargs -P。
剩下的就是处理xargs的细节问题了,比如如何分割(xargs、xargs -d、xargs -0),分割后如何划批(xargs -n、xargs -L),参数如何传递(xargs -i)。另外xargs还提供询问交互式处理(-p选项)和预先打印一遍命令的执行情况(-t选项),传递终止符(-E选项)等。
其实这里已经暗示了xargs处理的优先级或顺序了:先分割,再分批,然后传递到参数位。
分割有三种方法:独立的xargs、xargs -d和xargs -0。后两者可以配合起来使用,之所以不能配合独立的xargs使用,答案是显然的,指定了-d或-0选项意味着它不再是独立的。
分批方法从逻辑上说是两种:-n选项和-L选项。但我觉得还应该包含传递阶段的选项-i。假如-i不是分批选项,则它将接收分批的结果。然而事实并非如此,当-i选项指定在-n和-L选项之后,会覆盖-n或-L。后文中我将其当成分批选项来介绍和说明。
当然上述只是一个概括,更具体的还要看具体的选项介绍,而且很可能一个xargs中用不到这么多选项,但是理解这个很重要,否则在分割分批和传递上很容易出现疑惑。
1.2 文本意义上的符号和标记意义上的符号
在解释xargs和它的各种选项之前,我想先介绍一个贯穿xargs命令的符号分类:文本意义上的空格、制表符、反斜线、引号和非文本意义上的符号。我觉得理解它们是理解xargs分割和分批原理的关键。
文本意义上的空格、制表符、反斜线、引号:未经处理就已经存在的符号,例如文本的内容中出现这些符号以及在文件名上出现了这些符号都是文本意义上的。与之相对的是非文本意义的符号,由于在网上没找到类似的文章和解释,所以我个人称之为标记意义上的符号:处理后出现的符号,例如ls命令的结果中每个文件之间的制表符,它原本是不存在的,只是ls命令处理后的显示方式。还包括每个命令结果的最后的换行符,文件内容的最后一行结尾的换行符。
如下图,属于标记意义上的符号都用红色圆圈标记出来了。
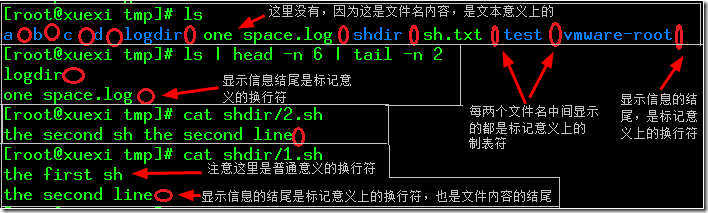
其实它们的关系有点类似于字面意义的符号和特殊符号之间的关系,就像有时候特殊符号需要进行转义才能表示为普通符号。
因为翻了百度、谷歌和一些书都没说这些方面的分类。但文本和非文本的符号在xargs分割的时候确实是区别对待的,所以我觉得有必要给个称呼好引用并说明它们,也就是说以上称呼完全是我个人的称呼。
1.3 分割行为之:xargs
[root@xuexi tmp]# cd /tmp
[root@xuexi tmp]# rm -fr *
[root@xuexi tmp]# mkdir a b c d test logdir shdir
[root@xuexi tmp]# touch “one space.log”
[root@xuexi tmp]# touch logdir/{1..10}.log
[root@xuexi tmp]# touch shdir/{1..5}.sh
[root@xuexi tmp]# echo “the second sh the second line” > shdir/2.sh
[root@xuexi tmp]# cat <<eof>shdir/1.sh
> the first sh
> the second line
> eof
对于xargs,它将接收到的stdout处理后传递到xargs后面的命令参数位,不写命令时默认的命令是echo。
[root@xuexi tmp]# cat shdir/1.sh | xargsthe first sh the second line
[root@xuexi tmp]# cat shdir/1.sh | xargs echothe first sh the second line
将分行处理掉不是echo实现的,而是管道传递过来的stdin经过xargs处理后的:将所有空格、制表符和分行符都替换为空格并压缩到一行上显示,这一整行将作为一个整体,这个整体的所有空格属性继承xargs处理前的符号属性,即原来是文本意义的或标记意义的在替换为空格后符号属性不变。这个整体可能直接交给命令或者作为stdout通过管道传递给管道右边的命令,这时结果将作为整体传递,也可能被xargs同时指定的分批选项分批处理。
如果想要保存制表符、空格等特殊符号,需要将它们用单引号或双引号包围起来,但是单双引号(和反斜线)都会被xargs去掉。
另外经过我的测试,单引号和双引号的存在让处理变的很不受控制,经常会影响正常的分割和处理。
如果不指定分批选项,xargs的一整行结果将作为一个整体输出,而不是分隔开的。也许看处理的结果感觉是分开处理的,例如下面的第一个命令,但是这是因为ls允许接受多个空格分开的参数,执行第二个命令,可以证明它确实是将整行作为整体传输给命令的。
[root@xuexi tmp]# find /tmp -maxdepth 1 | xargs ls
/tmp/sh.txt
/tmp:
a b c d logdir shdir sh.txt test
/tmp/a:
/tmp/b:
/tmp/c:
/tmp/d:
/tmp/.ICE-unix:
/tmp/logdir:
10.log 1.log 2.log 3.log 4.log 5.log 6.log 7.log 8.log 9.log
/tmp/shdir:
1.sh 2.sh 3.sh 4.sh 5.sh hell sh.txt
/tmp/test:
[root@xuexi tmp]# find /tmp -maxdepth 1 | xargs -p ls # -p选项后面有解释
ls /tmp /tmp/x.txt /tmp/logdir /tmp/b /tmp/test /tmp/d /tmp/vmware-root /tmp/sh.txt /tmp/c /tmp/shdir /tmp/a /tmp/one space.log /tmp/.ICE-unix ?…
如果对独立的xargs指定分批选项,则有两种分批可能:指定-n时按空格分段,然后划批,不管是文本意义的空格还是标记意义的空格,只要是空格都是-n的操作对象;指定-L或者-i时按段划批,文本意义的符号不被处理。
[root@xuexi tmp]# ls #one space.log是一个文件的文件名,只是包含了空格
a b c d logdir one space.log shdir sh.txt test vmware-root x.txt
[root@xuexi tmp]# ls | xargs -n 2
a b
c d
logdir one # one和space.log分割开了,说明-n是按空格分割的
space.log shdir
sh.txt test
vmware-root x.txt
[root@xuexi tmp]# ls | xargs -L 2
a b
c d
logdir one space.log # one space.log作为一个分段,文件名中的空格没有分割这个段
shdir sh.txt
test vmware-root
x.txt
[root@xuexi tmp]# ls | xargs -i -p echo {}
echo a ?…
echo b ?…
echo c ?…
echo d ?…
echo logdir ?…
echo one space.log ?… # one space.log也没有被文件名中的空格分割
echo shdir ?…
echo sh.txt ?…
echo test ?…
echo vmware-root ?…
echo x.txt ?…
1.4 使用xargs -p或xargs -t观察命令的执行过程
使用-p选项是交互询问式的,只有每次询问的时候输入y(或yes)才会执行,直接按enter键是不会执行的。
使用-t选项是在每次执行xargs后面的命令都会先在stderr上打印一遍命令的执行过程然后才正式执行。
使用-p或-t选项就可以根据xargs后命令的执行顺序进行推测,xargs是如何分段、分批以及如何传递的,这通过它们有助于理解xargs的各种选项。
[root@xuexi tmp]# ls | xargs -n 2 -t
/bin/echo a b # 先打印一次命令,表示这一次只echo两个参数:a和b
a b
/bin/echo c d # 表示这次只打印c和d
c d
/bin/echo logdir one
logdir one
/bin/echo space.log shdir
space.log shdir
/bin/echo sh.txt test
sh.txt test
/bin/echo vmware-root
vmware-root
[root@xuexi tmp]# ls | xargs -n 2 -p
/bin/echo a b ?…y # 询问是否echo a b
/bin/echo c d ?…a b
y # 询问是否echo c d,后面的…a b指示了echo c d是在前一个结果的基础上接着执行的
/bin/echo logdir one ?…c d
y
/bin/echo space.log shdir ?…logdir one
y
/bin/echo sh.txt test ?…space.log shdir
y
/bin/echo vmware-root ?…sh.txt test
y
vmware-root
从上面的-t和-p的结果上都可以知道每次传递两个参数。
1.5 分割行为之:xargs -d
xargs -d有如下行为:
? xargs -d可以指定分段符,可以是单个符号、字母或数字。如指定字母o为分隔符:xargs -d”o”。
? xargs -d是分割阶段的选项,所以它优先于分批选项(-n、-L、-i)。
? xargs -d不是先xargs再-d处理的,它是区别于独立的xargs的另一个分割选项。
xargs -d整体执行有几个阶段:
? 替换:将接收stdin的所有的标记意义的符号替换为\n,替换完成后所有的符号(空格、制表符、分行符)变成字面意义上的普通符号,即文本意义的符号。
? 分段:根据-d指定的分隔符进行分段并用空格分开每段,由于分段前所有符号都是普通字面意义上的符号,所以有的分段中可能包含了空格、制表符、分行符。也就是说除了-d导致的分段空格,其余所有的符号都是分段中的一部分。
? 输出:最后根据指定的分批选项来输出。这里需要注意,分段前后有特殊符号时会完全按照符号输出。
从上面的阶段得出以下两结论:
(1)xargs -d会忽略文本意义上的符号。对于文本意义上的空格、制表符、分行符,除非是-d指定的符号,否则它们从来不会被处理,它们一直都是每个分段里的一部分;
(2)由于第一阶段标记意义的符号会替换为分行符号,所以传入的stdin的每个标记意义符号位都在最终的xargs -d结果上分行了,但是它们已经是分段中的普通符号了,除非它们是-d指定的符号。
例如对ls的结果指定”o”为分隔符。
[root@xuexi tmp]# ls
a b c d logdir one space.log shdir sh.txt test vmware-root
[root@xuexi tmp]# ls | xargs -d”o” #指定字母”o”为分隔符
分段结果如图所示,图中每个封闭体都是一个分段,这些分段里可能包含了分行,可能包含了空格。
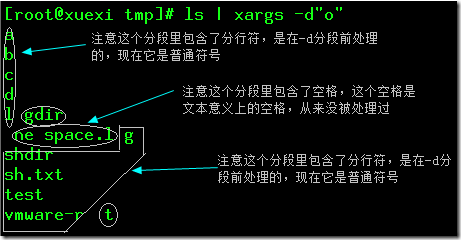
如果使用xargs -d时不指定分批选项,则整个结果将作为整体输出。
[root@xuexi tmp]# ls | xargs -d”o” -p
/bin/echo a
b
c
d
l gdir
ne space.l g
shdir
sh.txt
test
vmware-r t
x.txt
?…
如果指定了分批选项,则按照-d指定的分隔符分段后的段分批,这时使用-n、-L或-i的结果是一样的。例如使用-n选项来观察是如何分批的。
[root@xuexi tmp]# ls | xargs -d”o” -n 2 -t
/bin/echo a
b
c
d
l gdir # 每两段是一个批。
a
b
c
d
l gdir
# 注意这里有个空行。是因为段的分隔符处于下一段的行开头,它的前面有个\n符号会按符号输出。
/bin/echo ne space.l g
shdir
sh.txt
test
vmware-r # 打印中间两段
ne space.l g
shdir
sh.txt
test
vmware-r
/bin/echo t # 打印最后一段,
t # 注意t前面有空格,因为是两个分隔符o连在一起分割的,所以前面有个空格需要输出。
下面是最终显示结果。
[root@xuexi tmp]# ls | xargs -d”o” -n 2
a
b
c
d
l gdir
ne space.l g
shdir
sh.txt
test
vmware-r
t
再看看-n 1的输出。
[root@xuexi tmp]# ls | xargs -d”o” -n 1
a
b
c
d
l
gdir
ne space.l
g
shdir
sh.txt
test
vmware-r
t
[root@xuexi tmp]#
1.6 分割行为之:xargs -0
xargs -0的行为和xargs -d基本是一样的,只是-d是指定分隔符,-0是指定固定的\0作为分隔符。其实xargs -0就是特殊的xargs -d的一种,它等价于xargs -d”\0″。
xargs -0行为如下:
? xargs -0是分割阶段的选项,所以它优先于分批选项(-n、-L、-i)。
? xargs -0不是先xargs再-0处理的,它是区别于独立的xargs的另一个分割选项。
? xargs -0可以处理接收的stdin中的null字符(\0)。如果不使用 -0选项或– -null选项,检测到\0后会给出警告提醒,并只向命令传递非\0段。xargs -0和– -null是一样的效果。
xargs -0整体执行有几个阶段:
? 替换:将接收stdin的所有的标记意义的符号替换为\n,替换完成后所有的符号(空格、制表符、分行符)变成字面意义上的普通符号,即文本意义的符号。
? 分段:将检测到的null字符(\0)使用标记意义上的空格来分段,由于分段前所有符号都是普通字面意义上的符号,所以有的分段中可能包含了空格、制表符、分行符。也就是说除了-0导致的分段空格,其余所有的符号都是分段中的一部分。
如果没有检测到\0,则接收的整个stdin将成为一个不可分割的整体,任何分批选项都不会将其分割开,因为它只有一个段。
? 输出:最后根据指定的分批选项来输出。这里需要注意,分段前后有特殊符号时会完全按照符号输出。
根据上面的结论可知,xargs -0会忽略所有文本意义上的符号,它的主要目的是处理\0符号。
[root@xuexi tmp]# touch “one space.log”
[root@xuexi tmp]# ls | tr ” ” “\t” | xargs -0 #忽略文本意义上的制表符
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
# 注意有空行,因为命令结尾是一个标记意义上换行符号
[root@xuexi tmp]# ls | tr ” ” ” ” | xargs -0 #忽略文本意义上的空格
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
# 注意有空行
如果检测到\0而没有使用-0或–null处理则给出警告。注意警告后执行哪些文件。
[root@xuexi tmp]# ls | tr ” ” “\0″
a
b
c
d
logdir
onespace.log # 这里实际上是one\0space.log
shdir
sh.txt
test
vmware-root
[root@xuexi tmp]# ls | tr ” ” “\0” | xargs
xargs: Warning: a NUL character occurred in the input. It cannot be passed through in the argument list. Did you mean to use the –null option?
a b c d logdir one shdir sh.txt test vmware-root # 执行时将space.log忽略了,其余都执行
再例如,将所有的换行符换成null字符,结果中除了最前面的字母a和由于空格而不被\0影响的space.log,其余的由于全部有\0全部被忽略。
[root@xuexi tmp]# ls | tr “\n” “\0”
a bcdlogdirone space.logshdirsh.txttestvmware-root # 只有a的前面和space.log的前面是没有\0的
[root@xuexi tmp]# ls | tr “\n” “\0” | xargs
xargs: Warning: a NUL character occurred in the input. It cannot be passed through in the argument list. Did you mean to use the –null option?
a space.log # 所以只执行这两个
使用-0或–null来解决问题,也可以使用等价的xargs -d”\0″来解决。
[root@xuexi tmp]# ls | tr “\n” “\0” | xargs -0
或者
[root@xuexi tmp]# ls | tr “\n” “\0″ | xargs -d”\0”
a b c d logdir one space.log shdir sh.txt test vmware-root
如果使用xargs -0时不指定分批选项(-n、-L、-i),则处理后的结果将作为一个整体输出。
如果指定了分批选项,并且检测到了null字符,则以\0位的空格分段划批,这时使用-n、-L或-i的结果是一样的。例如使用-n选项来观察是如何分批的。
[root@xuexi tmp]# ls | tr “\n” “\0” | xargs -0 -n 3
a b c
d logdir one space.log
shdir sh.txt test
vmware-root x.txt
如果指定了分批选项,但没有检测到null字符,则整个结果将称为一个不可分割整体,这时使用分批选项是完全无意义的。
[root@xuexi tmp]# ls | xargs -0 -n 3 -p
/bin/echo a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
x.txt
?…
1.7 分批行为
分批用于指定每次传递多少个分段。有三种分批选项:-n,-L和-i。在本文的开头已经指明了为什么-i是分批选项,但是这里还是要介绍它逻辑上定义的功能:参数替换。
既然三种选项都是分批选项,如果在一个xargs中使用了多个分批选项,则它们之间必然会冲突,它们的规则是写在后面的生效,前面的分批选项被忽略。
1.7.1 xargs -n
xargs -n分两种情况:和独立的xargs一起使用,这时按照每个空格分段划批;和xargs -d或xargs -0一起使用,这时按段分批,即不以空格、制表符和分行符分段划批。
[root@xuexi tmp]# ls | xargs -n 3 -p #和独立的xargs一起使用,以空格分段划批
/bin/echo a b c ?…
/bin/echo d logdir one ?… # one和space.log被割开了
/bin/echo space.log shdir sh.txt ?…
/bin/echo test vmware-root x.txt ?…
/bin/echo ?…
[root@xuexi tmp]# ls | xargs -d”o” -n 3 -p # 和xargs -d一起使用,按段分批
/bin/echo a
b
c
d
l gdir
ne space.l ?…
/bin/echo g
shdir
sh.txt
test
vmware-r t
x.txt
?…
/bin/echo ?…
1.7.2 xargs -L
和-n选项类似,唯一的区别是-L永远是按段划批,而-n在和独立的xargs一起使用时是按空格分段划批的。
该选项的一个同义词是-l,但是man推荐使用-L替代-l,因为-L符合POSIX标准,而-l不符合。使用–max-lines也可以。
也许你man xargs时发现-L选项是指定传递时最大传递行数量的,man的结果如下图。但是通过下面的实验可以验证其实-L是指定传递的最大段数,也就是分批。

[root@xuexi tmp]# ls | xargs -L 3 -p #如果是指定传递的最大行数量,则一行就输出完了,这里却分了多行输出
/bin/echo a b c ?…
/bin/echo d logdir one space.log ?… # 这里可以证明-L和-n的区别
/bin/echo shdir sh.txt test ?…
/bin/echo vmware-root x.txt ?…
[root@xuexi tmp]# ls | xargs -d”o” -L 3 -p # 这就更能证明是指定最大传递的段数量了
/bin/echo a
b
c
d
l gdir
ne space.l ?…
/bin/echo g
shdir
sh.txt
test
vmware-r t
x.txt
?…
1.7.3 xargs -i和xargs -I
xargs -i选项在逻辑上用于接收传递的分批结果。
如果不使用-i,则默认是将分割后处理后的结果整体传递到命令的最尾部。但是有时候需要传递到多个位置,不使用-i就不知道传递到哪个位置了,例如重命名备份的时候在每个传递过来的文件名加上后缀.bak,这需要两个参数位。
使用xargs -i时以大括号{}作为替换符号,传递的时候看到{}就将被结果替换。可以将{}放在任意需要传递的参数位上,如果多个地方使用{}就实现了多个传递。
xargs -I(大写字母i)和xargs -i是一样的,只是-i默认使用大括号作为替换符号,-I则可以指定其他的符号、字母、数字作为替换符号,但是必须用引号包起来。man推荐使用-I代替-i,但是一般都使用-i图个简单,除非在命令中不能使用大括号,如touch {1..1000}.log时大括号就不能用来做替换符号。
例如下面的重命名备份过程。
[root@xuexi tmp]# ls logdir/
10.log 1.log 2.log 3.log 4.log 5.log 6.log 7.log 8.log 9.log
[root@xuexi tmp]# ls logdir/ | xargs -i mv ./logdir/{} ./logdir/{}.bak # 将分段传递到多个参数位
[root@xuexi tmp]# ls logdir/
10.log.bak 1.log.bak 2.log.bak 3.log.bak 4.log.bak 5.log.bak 6.log.bak 7.log.bak 8.log.bak 9.log.bak
但是我将“-i”选项划分在分批选项里,它默认一个段为一个批,每次传递一个批也就是传递一个段到指定的大括号{}位上。在稍后的分批选项的生效规则部分我会给出我的理由。
由于-i选项是按分段来传递的。所以尽管看上去等价的xargs echo和xargs -i echo {}并不等价。
[root@xuexi tmp]# ls | xargs echo
a b c d logdir one space.log shdir sh.txt test vmware-root
[root@xuexi tmp]# ls | xargs -i echo {}
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
既然使用-i后是分段传递的,这就意味着指定了它就无法实现按批传递多个参数了;并且如果使用多个大括号,意味着必须使用-i,那么也无法分批传递。
例如,想将数字1-10每3个数显示在start和end之间。效果如下:
start 1 2 3 end
start 4 5 6 end
start 7 8 9 end
start 10 end
由于指定了参数传递位置,所以必须使用-i,那么就无法一次传递3个数。要解决这个问题,就要想办法让每三个数分一次段然后使用-i传递,方法也就随之而来了。可以将每三个数分一次行写入一个文件。如:
[root@xuexi tmp]# cat <<eof>logdir/1.log
> 1 2 3
> 4 5 6
> 7 8 9
> 10
> eof
再使用xargs -i分批传递。
[root@xuexi tmp]# cat logdir/1.log | xargs -i echo “start {} end”
start 1 2 3 end
start 4 5 6 end
start 7 8 9 end
start 10 end
也可以使用多次xargs。很多时候无法解决分段的问题都可以通过多次使用xargs来解决。
[root@xuexi tmp]# echo {1..10} | xargs -n 3 | xargs -i echo “start {} end”
1.7.4 分批选项的生效规则
-i、-L、-n选项都是分批选项。它们的生效规则是,谁指定在后面,谁就生效。
下面给出证明。
下面-i放在-n、-L之后,结果是-n、-L被忽略。
[root@xuexi tmp]# ls | xargs -d”o” -n 2 -p -i echo {}
echo a
b
c
d
l ?… # 说明是一段一段输出,而不是两段一批输出,即-n选项被忽略
echo gdir
?…
echo ne space.l ?…
echo g
shdir
sh.txt
test
vmware-r ?…
echo ?…
echo t
x.txt
?…
[root@xuexi tmp]# ls | xargs -d”o” -L 3 -i -p echo {} # 和上面的结果是一模一样的,说明-L选项被忽略
echo a
b
c
d
l ?…
echo gdir
?…
echo ne space.l ?…
echo g
shdir
sh.txt
test
vmware-r ?…
echo ?…
echo t
x.txt
?…
下面是-L放在-n后,结果是-n被忽略。
[root@xuexi tmp]# ls | xargs -d”o” -n 2 -p -L 1 echo # 结果也是一段一段输出的,说明-n选项被忽略
echo a
b
c
d
l ?…
echo gdir
?…
echo ne space.l ?…
echo g
shdir
sh.txt
test
vmware-r ?…
echo ?…
echo t
x.txt
?…
根据上面的证明,其实也就给出了我认为-i选项是分批选项的理由,因为它覆盖了-n和-L,实际上在新的man xargs中已经给出了解释,它隐含”-L 1″。其实如果说-i包含分批并传递这两个作用更严格一点。
1.7.5 分批选项的一个典型应用
分批选项有时特别有用,例如脚本规定每次只能传输三个参数。有时候rm -rf的文件数量特别多的时候会提示参数列表太长而导致失败,这时就可以分批来按批删除,不仅rm -rf,其他很多本身就可以实现批量操作的命令都有可能出现这种参数列表过长的错误,如touch {1..10000000}也会提示错误。
假设目前在/tmp/longshuai/下有29W个.log文件,如果直接删除将会提示参数列表过长。
[root@xuexi tmp]# rm -fr /tmp/longshuai/*.log
-bash: /bin/rm: Argument list too long
这时如果使用xargs就可以分批丢给rm -fr处理了。下面一批10000个,删除29批。
[root@xuexi tmp]# cd /tmp/longshuai/ && ls | xargs -n 10000 rm -rf
如果不使用分批直接交给rm -rf也是一样可以执行成功的。如果想知道为什么可以请看后文xargs -s。
[root@xuexi tmp]# cd /tmp/longshuai/ && ls | xargs rm -rf
这里说下如何统计某个目录下的文件数量?ll后使用”-“开头来过滤出文件,然后使用wc统计行数。
[root@xuexi tmp]# ll /tmp/longshuai/ | grep “^-” | wc -l
1.8 终止行为之:xargs -E
指定终止符号,搜索到了指定的终止符就完全退出传递,命令也就到此结束。
-e选项也是,但是官方建议使用-E替代-e,因为-E是POSIX标准兼容的,而-e不是。
-E会将结果空格、制表符、分行符替换为空格并压缩到一行上显示。
据我测试,-E似乎只能和独立的xargs使用,和-0、-d配合使用时都会失效。那么稍后我就只测试和独立的xargs配合使用的情况了。
-E优先于-n、-L和-i执行。如果是分批选项先执行,则下面的第二个结果将压缩在一行上。
指定的终止符必须是完整的,例如想在遇到“xyz.txt”的符号终止时,只能指定完整的xyz.txt符号,不能指定.txt或者txt这样的符号。如何判断指定的终止符号是否完整,就-E与独立的xargs配合的情况而言分两种情况:如果没指定分批选项或者指定的分批选项是-n或者-L时,以空格为分割符,两个空格之间的段都是完整的;如果指定的分批选项是-i,则以段为分割符。
例如,下面的示例。观察实验结果中的one space.log分割的情况。
[root@xuexi tmp]# ls
a b c d logdir one space.log shdir sh.txt test vmware-root x.txt
[root@xuexi tmp]# ls | xargs -E one #不指定分批选项
a b c d logdir
[root@xuexi tmp]# ls | xargs -n 2 -E one #指定-n,one后面的所有的都终止传递
a b
c d
logdir
[root@xuexi tmp]# ls | xargs -L 2 -E”one” #同-n 选项
a b
c d
logdir
[root@xuexi tmp]# ls | xargs -i -E”one space.log” echo {} #和-i配合使用时指定完整的段才可以
a
b
c
d
logdir
[root@xuexi tmp]# ls | xargs -i -E”one” -p echo {} #非完整段终止失效
echo a ?…
echo b ?…
echo c ?…
echo d ?…
echo logdir ?…
echo one space.log ?…
echo shdir ?…
echo sh.txt ?…
echo test ?…
echo vmware-root ?…
echo x.txt ?…
1.9 xargs的处理总结
总结只有一张表。算是用来复习前面所述。
| 分割行为 |
特殊符号处理方式 |
分段方法 |
配合分批选项 |
分批方法 |
| xargs |
空格、制表符、分行符替换为空格,引号和反斜线删除。处理完后只有空格。如果空格、制表符和分行符使用引号包围则可以保留 |
结果继承处理前的符号性质(文本符号还是标记意义符号)。 |
-n |
以分段结果中的每个空格分段,进而分批。不管是文本还是标记意义的空格,只要是空格 |
| -L、-i |
以标记意义上的空格分段,进而分批 |
|
|
|
| 不指定 |
结果作为整体输出 |
|
|
|
| xargs -d |
xargs -d 不处理文本意义上的符号,所有标记意义上的符号替换为换行符\n,将-d指定的分割符替换为标记意义上的空格。结果中除了最后的空行和-d指定的分割符位的分段空格,其余全是文本意义上的符号 |
按照-d指定的符号进行分段,每个段中可能包含文本意义上的空格、制表符、甚至是分行符。 |
-n、-L、-i |
以标记意义上的符号(即最后的空行和-d指定分隔符位的空格)分段,进而分批。分段结果中保留所有段中的符号,包括制表符和分行符。 |
| 不指定 |
结果作为整体输出 |
|
|
|
| xargs -0 |
不处理文本意义上的符号,将非\0的标记意义上的符号替换为\n,将\0替换为空格。结果中除了最后空行和\0位的空格,其余都是文本意义上的符号 |
以替换\0位的空格分段,每个段中可能包含文本意义上的空格、制表符、甚至是分行符。如果没检测到\0,则只有一个不可分割的段。 |
-n、-L、-i |
检测到\0时,以标记意义上的符号(即最后的空行和\0位的空格)分段,进而分批。分段结果中保留所有段中的符号,包括制表符和分行符。 |
| 未检测到\0时,整个结果作为不可分割整体,使用分批选项是无意义的 |
|
|
|
|
| 不指定 |
结果作为整体输出 |
|
|
|
1.10 xargs与find的结合
xargs和find同属于一个rpm包findutils,xargs原本就是为find而开发的,它们之间的配合应当是天衣无缝的。
一般情况下它们随意结合都无所谓,按正常方式进行即可。但是当删除文件时,特别需要将文件名含有空白字符的文件纳入考虑。
[root@xuexi tmp]# touch one;touch space.log
[root@xuexi tmp]# ls
a b c d logdir one one space.log shdir sh.txt space.log test vmware-root
现在假设通过find搜索到了one space.log。
[root@xuexi tmp]# find -name “* *.log”
./one space.log
如果直接交给xargs rm -rf,由于xargs处理后不指定分批选项时以空格分段,所以改名了的行为将是rm -rf ./one space.log,这表示要删除的是当前目录下的one和当前目录下的space.log,而不是one space.log。
有多种方法可以解决这个问题。思路是让找到的“one space.log”成为一个段,而不是两个段。我给出了常见的两种。
方法一:通过常用的find的-print0选项使用\0来分隔而不是\n分隔,再通过xargs -0来配对保证one space.log的整体性。因为-print0后one space.log的前后各有一个\0,但是文件名中间没有。
[root@xuexi tmp]# find -name “* *.log” -print0 | xargs -0 rm -rf
当然,能使用-0肯定也能使用-d了。
[root@xuexi tmp]# find -name “* *.log” -print0 | xargs -d “x” rm -rf #随意指定非文件名中的字符都行,不一定非要\0
方法二:不在find上处理,在xargs上处理,只要通过配合-i选项,就能宣告它的整体性。
[root@xuexi tmp]# find -name “* *.log” | xargs -i rm -rf “{}”
相较而言,方法一使用的更广泛更为人所知,但是方法二更具有通用性,对于非find如ls命令也可以进行处理。
还可以使用tr将find的换行符换成其他符号再xargs分割配对也行。
除了find -print0可以输出\0字符,Linux中还有其他几个命令配合参数也可以实现:locate -0,grep -z或grep -Z,sort -z等。
1.11 xargs -s之为什么ls | xargs rm -rf能执行成功?
使用下面的示例配合图来解释。
[root@xuexi tmp]# cd logdir
[root@xuexi logdir]# touch {1..1000000}
-bash: /bin/touch: Argument list too long
[root@xuexi logdir]# echo {1..1000000} | xargs touch #执行的时候记得使用-p选项,否则慢慢等吧。
问题一:正常创建批量文件touch {1..1000000}是无法执行成功的,会提示参数列表过长。但是上面的最后一个命令为什么能执行成功?
问题二:xargs处理后如果不指定-n选项,那么它是整体传递的,如果这个整体非常非常大,如上面的100W个参数,按理说touch也是无法成功的。为什么成功了?
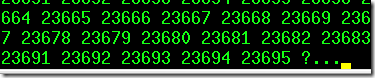
xargs有一个默认的选项-s,它指定每次传递的最大字节数,如果不显式指定-s,系统默认是128KB。也就是说如果一次传递的参数很多很大,那么将由系统自动分割为每128KB传递一次。这就是上面的命令能执行成功的原因。
上面的100W个参数,以差不多每个参数5个数字位加一个分段位空格共6个字节计算,128K有128*1024/6=21845个数字,这和我使用-p测试的询问位置是接近的,如下图,由于前10000个数字少于5个字节,所以比21845多一点。第二次停止的位置是45539,45539-23695=21844,这次传递的全是5个字节的,这和计算的结果几乎完全相同。
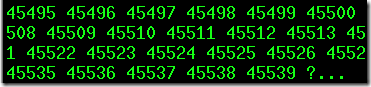
同理“ls | xargs rm -rf”也是一样的,如果参数列表非常大,则每次传递128K的参数给rm。
1.12 创建文件名包含分行符的文件
创建文件名包含空格的文件是一件很轻松的事情,但是想创建包含制表符、分行符甚至是其他特殊符号的文件呢?
因为xargs允许传递参数到命令的任意参数位,并且传递的参数还可以变换为包含各种形式的特殊符号,所以使用它可以轻松实现。例如创建包含分行符的文件。
[root@xuexi tmp]# ls
a b c d logdir one space.log shdir sh.txt test vmware-root
[root@xuexi tmp]# ls | xargs -0
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
在此基础上创建一个.sh文件,这个文件将奇形怪状,因为文件名竟然包含了分行符(Linux中文件名除了“/”和“\0”外所有字符都允许包含在内)。
[root@xuexi tmp]# ls | xargs -0 -i touch {}.sh
[root@xuexi tmp]# ls
a b d one space.log sh.txt vmware-root
a?b?c?d?logdir?one space.log?shdir?sh.txt?test?vmware-root?.sh c logdir shdir test
看上去只是有几个问号,但是使用?是无法定位它的。
[root@xuexi tmp]# find -name “*[\?]*” #搜索没结果
或者
[root@xuexi tmp]# rm -rf a #按两次tab键
a/
a^Jb^Jc^Jd^Jlogdir^Jone space.log^Jshdir^Jsh.txt^Jtest^Jvmware-root^J.sh
现在使用xargs就可以轻松显示它的文件名。
[root@xuexi tmp]# ls | xargs -0
a
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
.sh
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
不能直接使用xargs显示,因为它会压缩空白符号成空格。
[root@xuexi tmp]# ls | xargs
a a b c d logdir one space.log shdir sh.txt test vmware-root .sh b c d logdir one space.log shdir sh.txt test vmware-root
删除它。
[root@xuexi tmp]# rm -f a*.sh
如果想创建文件名只包含下面结果的abcd前四行的.sh文件呢?
[root@xuexi tmp]# ls | xargs -0
a
b
c
d
logdir
one space.log
shdir
sh.txt
test
vmware-root
参考下面的。
[root@xuexi tmp]# ls | xargs -n 1 -e”logdir” | xargs -0 -i touch {}.sh
这就需要理解前面介绍的xargs的分割和传递方法了。
也可以使用下面更简单容易理解的:
[root@xuexi tmp]# ls | head -n 4 | xargs -0 -i touch {}.sh
[root@xuexi tmp]# echo -e “a\nb\nc\nd” | xargs -0 -i touch {}.log
那么以相同的方法创建文件名中包含制表符的文件就easy了。
[root@xuexi tmp]# echo -e “a\tb\tc\td” | xargs -0 -i touch {}.log
1.13 高速并发处理之:xargs -P
使用xargs的分批行为,除了可以解决一些问题,还可以一次性将多个分批交给不同进程去处理,这些进程可以使用多个cpu执行,效率可谓大幅提高。
“-P N”选项可以指定并行处理的进程数量为N。不指定”-P”时,默认为1个处理进程,也就是串行执行。指定为0时,将尽可能多地开启进程数量。当xargs正在运行时(也就是还有分批正在处理),可以发送SIGUSR1信号给xargs进程,表示增加一个处理进程,同样,可以向xargs进程发送SIGUSR2进程,表示减少一个处理进程。但需要注意,即使发送SIGUSR2信号,xargs也不会中断正在执行任务的进程,也就是说,在某个进程处理当前分批任务结束之前,不会被中断,只有当前分批任务执行完毕,准备接下一个分批任务时,才会被xargs给杀掉。
例如,一个简单的sleep命令,在不使用”-P”的时候,默认是一个进程按批的先后进行处理:
[root@xuexi ~]# time echo {1..4} | xargs -n 1 sleep
real 0m10.011s
user 0m0.000s
sys 0m0.011s
总共用了10秒,因为每批传一个参数,第一批睡眠1秒,然后第二批睡眠2秒,依次类推,还有3秒、4秒,共1+2+3+4=10秒。
如果使用-P指定4个处理进程:
[root@xuexi ~]# time echo {1..4} | xargs -n 1 -P 4 sleep
real 0m4.005s
user 0m0.000s
sys 0m0.007s
结果总共才用了4秒,因为这4个分批同时交给了4个进程同时处理,所以取最长睡眠时间。
以下是一次并行执行过程中,CPU的使用情况:
[root@xuexi ~]# ps -eo pid,args,psr,pcpu | grep slee[p]
25566 xargs -n 1 -P 5 sleep 3 0.0
25567 sleep 20 1 0.0
25568 sleep 21 2 0.0
25569 sleep 22 0 0.0
25570 sleep 23 2 0.0
25571 sleep 24 3 0.0
在上面的结果中,启动了5个sleep进程,这5个进程分别用了cpu0、cpu1、cpu2和cpu3共4个cpu,因为我的虚拟机只给分配了4核心cpu。
那么,xargs的哪些选项可以通过”-P”的并行能力来提升效率?其实,只要能分批的选项,都可以使用”-P”,包括”-n”、”-L”和”-i”。在man xagrs中,只提到了”-n”和”-L”可以结合”-P”,并没有提到”-i”,但我前面已经验证过了,”-i”其实也是分批行为,也能结合”-P”的并行功能使用。
下面的示例,可以验证”-i -P”结合:
[root@xuexi ~]# time echo -n {1..4} | xargs -d” ” -i -P 4 sleep {}
real 0m4.003s
user 0m0.000s
sys 0m0.005s
如果需要发送信号,来增、减并行进程数量,可以向xargs进程发送SIGUSR1和SIGUSR2信号,例如:
kill -USR1 `pgrep -f “xargs”`
虽然xargs提供了这样的并行处理能力,但说实话,用到的机会并不多,它毕竟只是一个参数传递工具。我也专门写了一篇关于xargs高效并行的文章,见shell高效处理文本:xargs并行处理。另一个gnu工具parallel(装上epel源,yum -y install parallel即可)在并行处理上用的比较多,比如对一个巨大的文件利用sort进行排序时,使用parallel并行排序,可以大幅提升效率,即使sort自身已经足够完美。非常幸运的是,在你把xargs学到了这里,使用parallel将非常简单,因为它的选项和行为模式和xargs是基本一致的。
1.14 xargs一次性传递多个参数
默认情况下,xargs每次只能传递一条分割的数据到命令行中作为参数。但有时候想要让xargs一次传递2个、3个参数到命令行中。
例如有一个文件保存了wget想要下载的大量链接和链接对应要保存的文件名,一行链接一行文件名。格式如下:
https://www.xxx.yyy/a1
filename1
https://www.xxx.yyy/a2
filename2
https://www.xxx.yyy/a3
filename3
现在想要通过读取这个文件,将每一个URL和对应的文件名传递给wget去下载:
wget ‘{URL}’ -O ‘{FILENAME}’
xargs自身的功能无法一次性传递多个参数(parallel命令可以,而且方式多种),只能寻求一些技巧来实现。
cat url.txt | xargs -n2 bash -c ‘wget “$1” -O “$2″‘
1.15 xargs的不足之处(此处必看)
其实是xargs的限制和缺点,但因为通过”-i”选项方便演示,所以此处使用”-i”选项。注意,不是”-i”选项的缺陷。
由于xargs -i传递数据时是在shell执行xargs命令的时候,根据shell解析命令行的流程 ,xargs后的命令如果有依赖于待传递数据的表达式,则无法正确执行。
例如,无法通过xargs传递数值做正确的算术扩展:
[root@xuexi logdir]# echo 1 | xargs -I “x” echo $((2*x))
0
无法将数据传递到命令替换中。
[root@xuexi ~]# echo /etc/fstab | xargs -i `cat {}`
cat: {}: No such file or directory
参考下图的shell命令行解析过程。
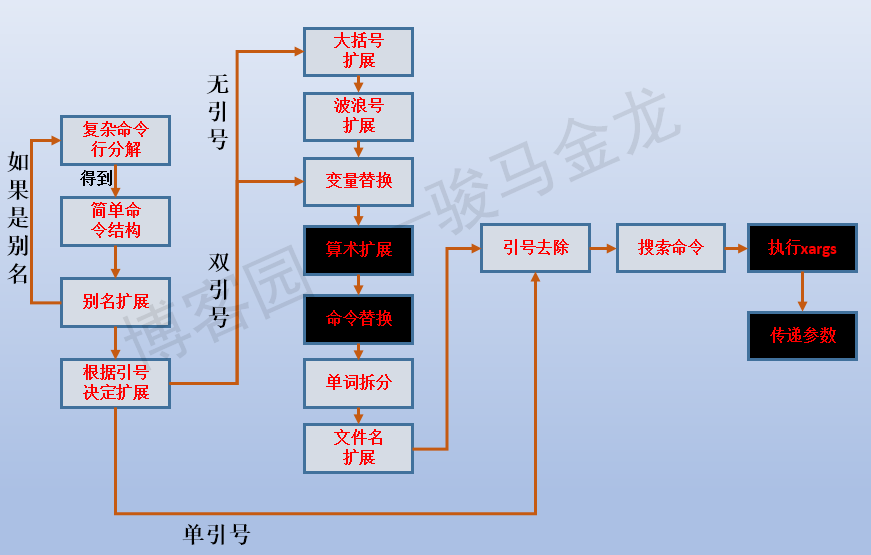
这时要通过xargs正确实现目标,只能改变方法或寻找一些小技巧,例如:
[root@xuexi ~]# echo 1 | xargs -i expr 2 \* {} # 感谢楼下评论者提供的expr思路
2
[root@xuexi ~]# echo /etc/fstab | xargs -i cat $(echo {})
另外,xargs无法处理bash内置命令。例如:
[root@xuexi ~]# echo /etc | xargs -i cd {}
xargs: cd: No such file or directory
Linux 命令大全






z977690557
977***557@qq.com
awk、sed、grep更适合的方向:
关于awk内建变量个人见解,简单易懂
解释一下变量:
变量:分为内置变量和自定义变量;输入分隔符FS和输出分隔符OFS都属于内置变量。
内置变量就是awk预定义好的、内置在awk内部的变量,而自定义变量就是用户定义的变量。
自定义变量的方法