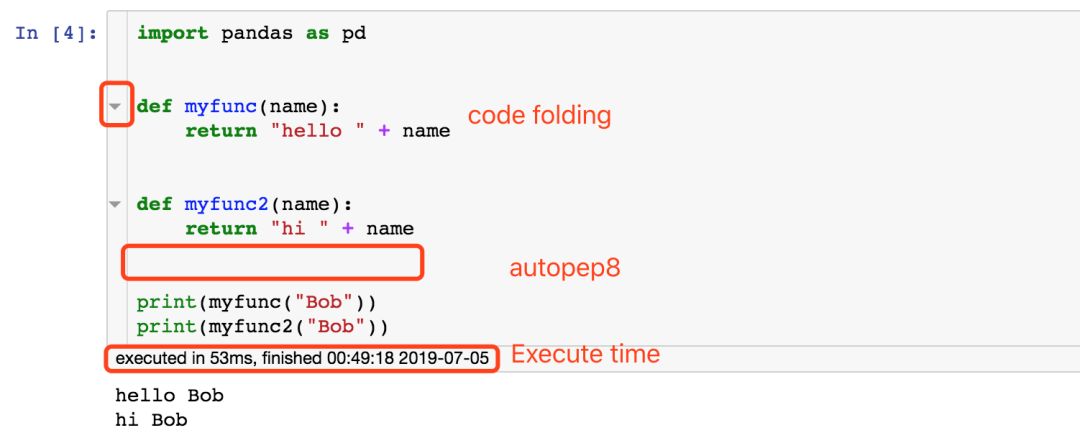
这篇文章主要介绍了Selenium启动Chrome时配置选项详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
Selenium操作浏览器是不加载任何配置的,网上找了半天,关于Firefox加载配置的多点,Chrome资料很少,下面是关于加载Chrome配置的方法:
一、加载所有Chrome配置
用Chrome地址栏输入chrome://version/,查看自己的“个人资料路径”,然后在浏览器启动时,调用这个配置文件,代码如下:
|
1
2
3
4
5
|
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('--user-data-dir=C:\Users\Administrator\AppData\Local\Google\Chrome\User Data')
driver = webdriver.Chrome(chrome_options=option)
|
二、修改浏览器的User-Agent来伪装你的浏览器访问手机m站
|
1
2
3
4
5
6
|
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('--user-agent=iphone')
driver = webdriver.Chrome(chrome_options=option)
driver.get('http://www.taobao.com/')
|
三、浏览器启动时安装crx扩展
|
1
2
3
4
5
6
|
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_extension('d:\crx\AdBlock_v2.17.crx')
driver = webdriver.Chrome(chrome_options=option)
driver.get('http://www.taobao.com/')
|
可以去https://sites.google.com/a/chromium.org/chromedriver/capabilities查看更多,或者去http://stackoverflow.com/查找。
下边是收集的一些配置信息:
一些Chrome的地址栏命令(这些命令会不停的变动,所有不一定都是好用的)
在Chrome的浏览器地址栏中输入以下命令,就会返回相应的结果。这些命令包括查看内存状态,浏览器状态,网络状态,DNS服务器状态,插件缓存等等。
about:version – 显示当前版本
about:memory – 显示本机浏览器内存使用状况
about:plugins – 显示已安装插件
about:histograms – 显示历史记录
about:dns – 显示DNS状态
about:cache – 显示缓存页面
about:gpu -是否有硬件加速
about:flags -开启一些插件 //使用后弹出这么些东西:“请小心,这些实验可能有风险”,不知会不会搞乱俺的配置啊!
chrome://extensions/ – 查看已经安装的扩展
其他的一些关于Chrome的实用参数及简要的中文说明(使用方法同上,当然也可以在shell中使用)
–user-data-dir=”[PATH]” 指定用户文件夹User Data路径,可以把书签这样的用户数据保存在系统分区以外的分区。
–disk-cache-dir=”[PATH]“ 指定缓存Cache路径
–disk-cache-size= 指定Cache大小,单位Byte
–first run 重置到初始状态,第一次运行
–incognito 隐身模式启动
–disable-javascript 禁用Javascript
–omnibox-popup-count=”num” 将地址栏弹出的提示菜单数量改为num个。我都改为15个了。
–user-agent=”xxxxxxxx” 修改HTTP请求头部的Agent字符串,可以通过about:version页面查看修改效果
–disable-plugins 禁止加载所有插件,可以增加速度。可以通过about:plugins页面查看效果
–disable-javascript 禁用JavaScript,如果觉得速度慢在加上这个
–disable-java 禁用java
–start-maximized 启动就最大化
–no-sandbox 取消沙盒模式
–single-process 单进程运行
–process-per-tab 每个标签使用单独进程
–process-per-site 每个站点使用单独进程
–in-process-plugins 插件不启用单独进程
–disable-popup-blocking 禁用弹出拦截
–disable-plugins 禁用插件
–disable-images 禁用图像
–incognito 启动进入隐身模式
–enable-udd-profiles 启用账户切换菜单
–proxy-pac-url 使用pac代理 [via 1/2]
–lang=zh-CN 设置语言为简体中文
–disk-cache-dir 自定义缓存目录
–disk-cache-size 自定义缓存最大值(单位byte)
–media-cache-size 自定义多媒体缓存最大值(单位byte)
–bookmark-menu 在工具 栏增加一个书签按钮
–enable-sync 启用书签同步
常用:
–single-process 单进程运行Google Chrome
–start-maximized 启动Google Chrome就最大化
–disable-java 禁止Java
–no-sandbox 非沙盒模式运行
全部:(下面的没有进行翻译,仔细看下应该都看得懂. ~ ~)
–disable-hang-monitor
Suppresses hang monitor dialogs in renderer processes.
–disable-metrics
Completely disables UMA metrics system.
–disable-metrics-reporting
Disables only the sending of metrics reports. In contrast to kDisableMetrics, this executes all the code that a normal client would use for reporting, except the report is dropped rather than sent to the server. This is useful for finding issues in the metrics code during UI and performance tests.
–assert-test
Causes the browser process to throw an assertion on startup.
–renderer-assert-test
Causes the renderer process to throw an assertion on launch.
–crash-test
Performs a crash test when the browser is starte.
–renderer-crash-test
Causes the renderer process to crash on launch.
–renderer-startup-dialog
Use this argument when you want to see the child processes as soon as Chrome start.
–plugin-startup-dialog
Causes the plugin process to display a dialog on launch.
–testshell-startup-dialog
Causes the test shell process to display a dialog on launch.
–plugin-launcher
Specifies a command that should be used to launch the plugin process. Useful
for running the plugin process through purify or quantify. Ex:
–plugin-launcher=”path\to\purify /Run=yes.
–plugin-launche.
–channel
The value of this switch tells the child process which
IPC channel the browser expects to use to communicate with it.
–testing-channel
The value of this switch tells the app to listen for and broadcast
testing-related messages on IPC channel with the given ID.
–homepage
The value of this switch specifies which page will be displayed
in newly-opened tabs. We need this for testing purposes so
that the UI tests don’t depend on what comes up for http://google.com.
–start-renderers-manually
When this switch is present, the browser will throw up a dialog box
asking the user to start a renderer process independently rather
than launching the renderer itself. (This is useful for debugging..
–renderer
Causes the process to run as renderer instead of as browser.
–renderer-path
Path to the executable to run for the renderer subproces.
–plugin
Causes the process to run as plugin hos.
–single-process
Runs the renderer and plugins in the same process as the browse.
–process-per-tab
Runs each set of script-connected tabs (i.e., a BrowsingInstance) in its own
renderer process. We default to using a renderer process for each
site instance (i.e., group of pages from the same registered domain with
script connections to each other).
–process-per-site
Runs a single process for each site (i.e., group of pages from the same
registered domain) the user visits. We default to using a renderer process
for each site instance (i.e., group of pages from the same registered
domain with script connections to each other).
–in-process-plugins
Runs plugins inside the renderer proces.
–no-sandbox
Runs the renderer outside the sandbox.
–safe-plugins
Runs the plugin processes inside the sandbox.
–trusted-plugins
Excludes these plugins from the plugin sandbox.
This is a comma separated list of plugin dlls name and activex clsid.
–test-sandbox
Runs the security test for the sandbox.
–user-data-dir
Specifies the user data directory, which is where the browser will look
for all of its state.
–app
Specifies that the associated value should be launched in “application” mode.
–upload-file
Specifies the file that should be uploaded to the provided application. This
switch is expected to be used with –app option.
–dom-automation
Specifies if the dom_automation_controller_ needs to be bound in the
renderer. This binding happens on per-frame basis and hence can potentially
be a performance bottleneck. One should only enable it when automating
dom based tests.
–plugin-path
Tells the plugin process the path of the plugin to loa.
–js-flags
Specifies the flags passed to JS engin.
–geoid
The GeoID we should use. This is normally obtained from the operating system
during first run and cached in the preferences afterwards. This is a numeric
value; see http://msdn.microsoft.com/en-us/library/ms776390.aspx .
–lang
The language file that we want to try to open. Of the form
language[-country] where language is the 2 letter code from ISO-639.
–debug-children
Will add kDebugOnStart to every child processes. If a value is passed, it
will be used as a filter to determine if the child process should have the
kDebugOnStart flag passed on or not.
–debug-on-start
Causes the process to start the JIT debugger on itself (mainly used by –debug-children.
–wait-for-debugger-children
Will add kWaitForDebugger to every child processes. If a value is passed, it
will be used as a filter to determine if the child process should have the
kWaitForDebugger flag passed on or not.
–wait-for-debugger
Waits for a debugger for 60 second.
–log-filter-prefix
Will filter log messages to show only the messages that are prefixed
with the specified valu.
–enable-logging

Force logging to be enabled. Logging is disabled by default in release
builds.
–dump-histograms-on-exit
Dump any accumualted histograms to the log when browser terminates (requires
logging to be enabled to really do anything). Used by developers and test
scripts.
–disable-logging
Force logging to be disabled. Logging is enabled by default in debug
builds.
–log-level
Sets the minimum log level. Valid values are from 0 to 3:
INFO = 0, WARNING = 1, LOG_ERROR = 2, LOG_FATAL = 3.
–remote-shell-port
Enable remote debug / automation shell on the specified por.
–uninstall
Runs un-installation steps that were done by chrome first-run.
–omnibox-popup-count
Number of entries to show in the omnibox popup.
–uninstallomnibox-popup-count
Removes the previous set suggestion coun.
–automation-channel
The value of this switch tells the app to listen for and broadcast
automation-related messages on IPC channel with the given ID.
–restore-last-session
Indicates the last session should be restored on startup. This overrides
the preferences value and is primarily intended for testing.
–record-mode
–playback-mode
Chrome supports a playback and record mode. Record mode saves *everything*
to the cache. Playback mode reads data exclusively from the cache. This
allows us to record a session into the cache and then replay it at will.
–no-events
Don’t record/playback events when using record & playback.
–hide-icons
–show-icons
Make Windows happy by allowing it to show “Enable access to this program”
checkbox in Add/Remove Programs->Set Program Access and Defaults. This
only shows an error box because the only way to hide Chrome is by
uninstalling it.
–make-default-browser
Make Chrome default browse.
–proxy-server
Use a specified proxy server, overrides system settings. This switch only
affects HTTP and HTTPS requests.
–dns-log-details
–dns-prefetch-disable
Chrome will support prefetching of DNS information. Until this becomes
the default, we’ll provide a command line switch.
–debug-print
Enables support to debug printing subsystem.
–allow-all-activex
Allow initialization of all activex controls. This is only to help website
developers test their controls to see if they are compatible in Chrome.
Note there’s a duplicate value in activex_shared.cc (to avoid
dependency on chrome module). Please change both locations at the same time.
–disable-dev-tools
Browser flag to disable the web inspector for all renderers.
–always-enable-dev-tools
Enable web inspector for all windows, even if they’re part of the browser.
Allows us to use our dev tools to debug browser windows itself.
–memory-model
Configure Chrome’s memory model.
Does chrome really need multiple memory models? No. But we get a lot
of concerns from individuals about how the changes work on *their*
system, and we need to be able to experiment with a few choices.
–tab-count-to-load-on-session-restore
Used to set the value of SessionRestore::num_tabs_to_load_. See session_restore.h for details.
const wchar_t kTabCountToLoadOnSessionRestore[] .
–memory-profile
Enable dynamic loading of the Memory Profiler DLL, which will trace
all memory allocations during the run.
–enable-file-cookies
By default, cookies are not allowed on file://. They are needed in for
testing, for example page cycler and layout tests. See bug 1157243.
–start-maximized
Start the browser maximized, regardless of any previous settings.
TODO(pjohnson): Remove this once bug 1137420 is fixed. We are using this
as a workaround for not being able to use moveTo and resizeTo on a
top-level window.
–enable-watchdog
Spawn threads to watch for excessive delays in specified message loops.
User should set breakpoints on Alarm() to examine problematic thread.
Usage: -enable-watchdog=[ui][io]
Order of the listed sub-arguments does not matter.
–first-run
Display the First Run experience when the browser is started, regardless of
whether or not it’s actually the first run.
–message-loop-strategy
–message-loop-histogrammer
Enable histograming of tasks served by MessageLoop. See about:histograms/Loop
for results, which show frequency of messages on each thread, including APC
count, object signalling count, etc.
–import
Perform importing from another browser. The value associated with this
setting encodes the target browser and what items to import.
–silent-dump-on-dcheck
Change the DCHECKS to dump memory and continue instead of crashing.
This is valid only in Release mode when –enable-dcheck is specified.
–disable-prompt-on-repost
Normally when the user attempts to navigate to a page that was the result of
a post we prompt to make sure they want to. This switch may be used to
disable that check. This switch is used during automated testing.
–disable-popup-blocking
Disable pop-up blocking.
–disable-javascript
Don’t execute JavaScript (browser JS like the new tab page still runs).
–disable-java
Prevent Java from running.
–disable-plugins
Prevent plugins from running.
–disable-images
Prevent images from loading.
–use-lf-heap
Use the low fragmentation heap for the CRT.
–gears-plugin-path
Debug only switch to specify which gears plugin dll to load.
–gears-in-renderer
Switch to load Gears in the renderer process.
–enable-p13n
–javascript-debugger-path
Allow loading of the javascript debugger UI from the filesystem.
–new-http
Enable new HTTP stack.
到此这篇关于Selenium启动Chrome时配置选项详解的文章就介绍到这了,更多相关Selenium启动Chrome内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
Selenium常见异常解析及解决方案示范
更新时间:2020年04月10日 12:01:38 作者:临渊
这篇文章主要介绍了Selenium常见异常解析及解决方案示范,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
pycharm中导入selenium报错
现象: pycharm中输入from selenium import webdriver, selenium标红
原因1: pycharm使用的虚拟环境中没有安装selenium,
解决方法: 在pycharm中通过设置或terminal面板重新安装selenium
原因2: 当前项目下有selenium.py,和系统包名冲突导致,
解决方法,重命名这个文件
驱动及本地服务类异常
未找到响应的浏览器驱动
WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
或
WebDriverException: Message: 'chromedriver' executable needs to be in PATH.
原因: 查找不到对应的浏览器驱动
解决方法: 下载浏览器对应版本的chromedriver或geckodrivergeckodriver
放到脚本当前文件夹下或将路径配置到环境变量中, 或放到Python目录的Scripts下(一般情况下Python的Scripts目录在环境变量中), 或使用浏览器选项options指定驱动路径
未找到浏览器
WebDriverException: Message Can not connect to the Service chromedriver
org.openqa.selenium.WebDriverException: Failed to connect to binary FirefoxBinary
原因: 在默认路径下未找到Firefox浏览器
解决方法: 重新安装Firefox浏览器
驱动和浏览器不匹配
SessionNotCreatedException: Message: session not created:
this version of ChromeDriver only supports Chrome version 76
原因: 当前使用chromedriver只支持Chrome76版本
解决方法: 查看本地Chrome浏览器的版本, 下载对应的chromedriver
驱动被防火墙拦截
WebDriverException: Message: Can not connect to the Service IEDriverServer.exe
原因: iedriverserver.exe被防火墙拦截
解决方法: 防火墙设置允许
连接不上chromedriver服务
WebDriverException: Message: Can not connect ot the Service chromedriver
原因: 脚本通过127.0.0.1这个ip访问本地chromedriver服务, hosts中未配置 127.0.0.1指向localhost
解决办法: 配置本地hosts, 添加:127.0.0.1 localhost
6.RemoteDriverServerException: 远程服务器异常, 解决方法: 确认webdriver.Remote()中的远程Webdriver服务是否OK
7. ErrorInResponseException: Webdriver服务器响应异常, 解决方法, 根据具体报错信息分析
找不到类异常: 定位/获取属性/切换警告框,Frame, 窗口
- NoSuchElementException: 找不到元素, 解决方法: 前面加上sleep等待后重试,或换一种定位方式
- NoSuchAttributeException: 元素没有这个属性, 解决方法: 确认定位到的元素是否目标元素, 检查属性拼写
- NoAlertPresentException:没有找到alert弹出框, 解决方法: 观察页面,查看是否有弹框出现, 加上等待或作为偶现元素处理
- NoSuchFrameException:没有找到指定的frame或iframe, 解决方法: 查看拼写或切换使用frame的id/name/index/定位到的frame
- NoSuchWindowException: 没找到窗口句柄指定的窗口, 解决方法: 查看使用的窗口句柄变量拼写
- UnexpectedAlertPresentException: 出现了弹框而未处理, 解决方法: 切换到警告框并处理, 如果偶现,使用try…except处理偶现弹框
- InvalidSwitchToTargetException: 切换到指定frame或窗口报错, 解决方法: 查看相应的frame或窗口是否能定位到
- UnexpectedTagNameException: 使用Tag Name不合法, 解决方法: 检查拼写或使用css selector/xpath
- TimeoutException:查找元素或操作超时, 解决方法, 稍后重试
元素操作异常类: 隐藏/不可操作状态
- ElementNotVisibleException:元素不可见异常, selenium不能直接操作隐藏元素, 解决方法: 加上等待, 使用正常步骤使元素显示, 或使用js找到该元素的祖先节点的隐藏属性(通常为styple=”display: none”), 移除该属性然后定位操作.
- StaleElementReferenceException: 陈旧元素引用异常, 页面刷新或跳转后使用了之前定位到的元素, 解决方法: 重新定位元素并操作
- InvalidElementStateException: 元素状态异常 元素只读/不可点击等, 解决方法, 等待或使用js移除元素readonly/disable等限制属性后操作
- ElementNotSelectableException:元素不可被选中, 解决方法: 确认原始是否为select标签, 是否禁用
- InvalidSelectorException: 使用的定位方法不支持或xpath语法错误, 未返回元素, 解决方法: 检查使用的元素定位器是否拆包, 使用find_element()方法是, 第一个参数为’class name’, ‘link text’, ‘particial link text’ ‘css selector’, 空格分开, 非下划线连接, 建议使用By.CLASS_NAME的方式. 使用chrome开发着工具+Ctrl+F搜索验证自己写的xpath语法.
- MoveTargetOutOfBoundsException: 使用ActionChains的move方法时移动到的位置不合适
Cookie存取相关异常
- InvalidCookieDomainException: Cookie相应的域名无效
- UnableToSetCookieException: 设置Cookie异常
IME输入法引擎异常
- ImeNotAvailableException: 服务器不支持输入法
- ImeActivationFailedException: 输入法激活异常
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。





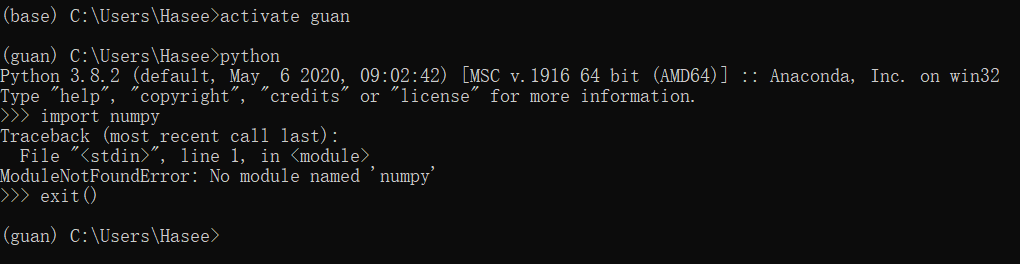

 4. 常用快捷(键)操作:
4. 常用快捷(键)操作: