Anaconda是个什么东东?
一、Anaconda 有什么用?
是一个安装、管理python相关包的软件,还自带python、Jupyter Notebook、Spyder,有管理包的conda工具,非常有用。
二、如何安装Anaconda?
很简单:
1、去官网https://www.anaconda.com/products/individual下载安装文件,不到500M。
2、双击安装。可以参考 http://www.360doc.com/content/20/0511/06/29876786_911481951.shtml 具体细节。
3、安装完成。
三、pip 和 conda 的区别
我简单的理解:
pip 是在python 环境中管理python包的工具
conda 是在conda环境中管理python包和其它包(例如C语言包)的工具
二者是不同的东西,不可以混用,它们安装的东西不在一个地方。
四、conda 常用的命令 (在终端中使用这些命令。打开图形界面AnacondaNavigator ,左侧Environment,点击小三角形,选中Open Terminal)
conda –version #查看conda版本,验证是否安装
conda update conda #更新至最新版本,也会更新其它相关包
conda update –all #更新所有包
conda update name #更新指定的包
conda create -n env_name package_name #创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号,
例如:conda create -n python2 python=python2.7 numpy pandas,创建了python2环境,python版本为2.7,同时还安装了numpy pandas包
activate env_name #切换至env_name 环境
source activate env_name#以上不行使用这
deactivate name #退出环境(返回默认环境)
source deactivate env_name#以上不行使用这
conda info -e #显示所有已经创建了的环境
conda create –name new_env_name –clone old_env_name #复制old_env_name为new_env_name
conda remove –name env_name –all #删除环境
conda list #查看所有已经安装的包
conda install package_name #在当前环境中安装包
conda install –name env_name package_name #在指定环境中安装包
conda remove — name env_name package #删除指定环境中的包
conda remove package #删除当前环境中的包
conda env list #查看所有的环境
conda env export > environment.yaml // 导出当前环境的包信息
conda env create -f environment.yaml // 用配置文件创建新的虚拟环境
五、python 虚拟环境
1)什么是虚拟环境?
把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。
比如下载完 Anaconda 之后,默认的就是 base 环境。
2)为什么要用虚拟环境?
因为在开发当中,我们需要根据不同的需求,下载不同的框架库,或者不同的版本。有了虚拟环境,我们可以为
不同的项目配置不同的运行环境,这样多个项目可以同时运行。
3)如何使用虚拟环境?
创建、激活、退出、删除。详见上面的命令,不再赘述。
注:新创建的环境除了python自带的一些官方包之外是没有其它包的,是一个比较干净的环境。例如我们可以在终端输入 python 打开 python的解释器试一下:
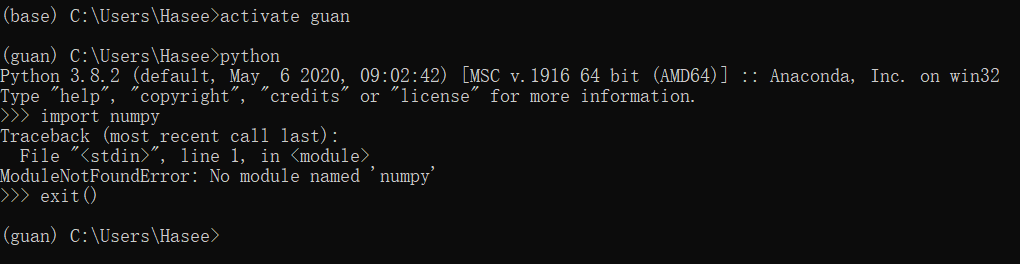
接下来我们可以在此环境中使用上述命令安装和卸载第三方包。
补充:Anaconda 所谓的创建虚拟环境,实际上就是在本地安装了一个真实的python环境,具体位置就在下面这个文件夹里
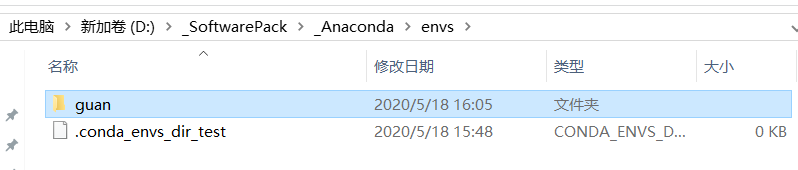
我们可以使用conda 命令随意切换当前的python 环境,使用不同版本的解释器和不同版本的包去运行python脚本。
六、Anaconda 与 pyCharm 连接
在工作环境中我们会集成开发环境去编码, 这里推荐JB公司的pycharm, 而pycharm也能很方便的和anaconda的虚拟环境结合
在Setting => Project => Project Interpreter 里面修改 Project Interpreter , 点击齿轮标志再点击Add Local为你某个环境的python.exe解释器就行了
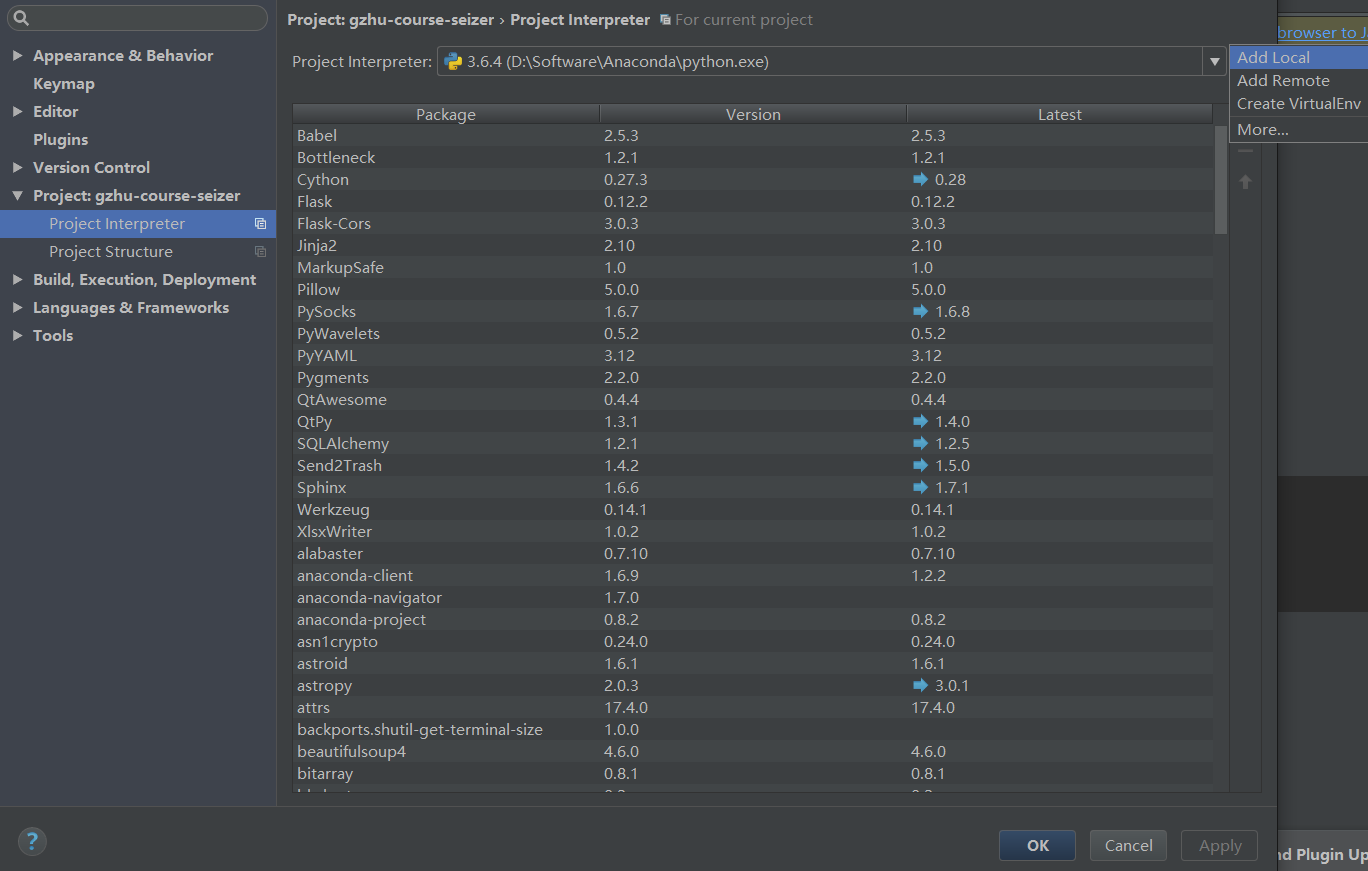
D:\Software\Anaconda\envs\learn, 可以看到这时候下面的依赖包也变成了learn环境中的包了.Anaconda 讲解 与 jupyter notebook 搭配
方便管理各类python库环境,来回切各类环境,因为有的时候别人的代码运行需要特定的python版本,所以新建一个python环境非常方便。
安装
Anaconda官方下载之后,Mac 下直接用命令行来安装吧:
$ bash ~/Downloads/Anaconda3-5.3.1-MacOSX-x86_64.sh // python3版本
1
安装过程中会让你输入yes 或 回车健,一路按照提示输入就行,没啥好犹豫的,安装后验证一下:
$ source ~/.bash_profile // 让环境变量生效
$ conda -V
# conda 4.7.12 // 输出conda 版本号
出现 conda 4.7.12 就说明安装成功。
常用命令使用
1、创建环境
$ conda create -n myenv python=3.7
生成指定python 3.7版本的环境,myenv 是环境名
2、多个环境建立好了,具体让那个生效呢?
$ conda activate myenv
有的环境利用的是 source activate ,这个跟安装的conda环境有关。指定要生效的环境名。
3、退出环境
$ conda deactivate
4、也可以删除 环境
$ conda remove –name myenv –all
5、查看环境列表
$ conda env list
1
6、查看环境中的安装库
conda list -n myenv
1
可以了解环境中
7、搜索包
conda search XXX
1
8、安装包
$ conda install XXX
1
这里的安装没有指定环境,其实是所有环境都可以使用这个库,相当于本地安装库一样
9、移除包
$ conda remove XXX
1
2
这个移除类似移除本地的库
10、安装库 到指定环境
$ conda install -n myenv XXX
1
库包管理
除了利用conda来安装包,还可以用pip来安装包,这是python 推荐的安装工具,
1、pip list
查看本地环境安装的那些包,你说如果我在一个conda 环境下可以使用这个命令,可以看到该环境安装的库包嘛?
2、pip install xxx
安装库包
pip install SomePackage==1.0.4 # 指定版本
pip install ‘SomePackage>=1.0.4’ # 最小版本
1
2
环境管理
新建环境是一个特别赶紧的环境,我们可以指定一个公共的环境,这里面放一些基本的库包,然后有特殊的库包要求,可以复制这个环境创建新环境,然后在新环境中安装特殊要求的库包版本号。
假设我们的基本库包为common环境,我们可以在这个环境中安装一些基本的包:
conda install scikit-learn
conda install numpy
conda install pandas
conda install lightgbm
通过复制功能,新建一个环境newenv:
conda create -n newenv –clone common
这样newenv 环境 包含了common 环境的库包,不需要额外安装。
环境管理注意要点
上面是相关命令,但是Anaconda环境管理还没讲到,这是他的主要优势,建议:
尽可能使用pip安装一些公有包
用conda 安装一些 特殊版本的包
经可能的给指定 环境 安装库
目前已经知道的知识点是:
conda创建的虚拟环境,只能创建当前与python版本相同的虚拟环境,所以它所含的包也是当前环境中pip安装过的包
有人补充:
conda install的package似乎是在anaconda\pkgs下,
而pip install的package是在anaconda\Lib\site-packages下。
推荐使用pip管理包(pip是python官方推荐的包管理器)
如果你在base环境,pip install的package应该就是安装在anaconda\Lib\site-packages下,然后其他虚拟环境下的使用python packages时优先搜索该虚拟环境下的package,如果没有它就搜索base环境下的package,也就是base环境下的package是可以被其他虚拟环境使用的,如果你进入其他虚拟环境下使用pip install,那么下载的包就只在这个虚拟环境中
配置镜像源
配置镜像源到目的是为来快速安装库包,毕竟配置为国内的镜像源下载库包更快,命令如下:
conda config –add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config –add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config –set show_channel_urls yes
使用 如下命令可以看到以下是否添加成功:
conda info
1
这个命令会打印出镜像信息。
与jupyter notebook关联
主要参考这篇文章,讲解的比较到位。https://zhuanlan.zhihu.com/p/29564719。
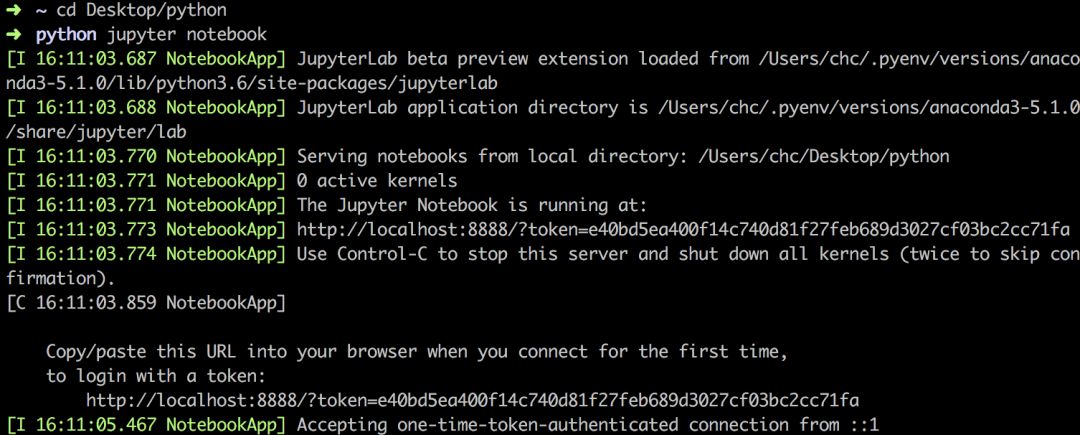
基本上安装来annaconda ,也安装了jupyter notebook,通过命令就可以打开:
jupyter notebook
1
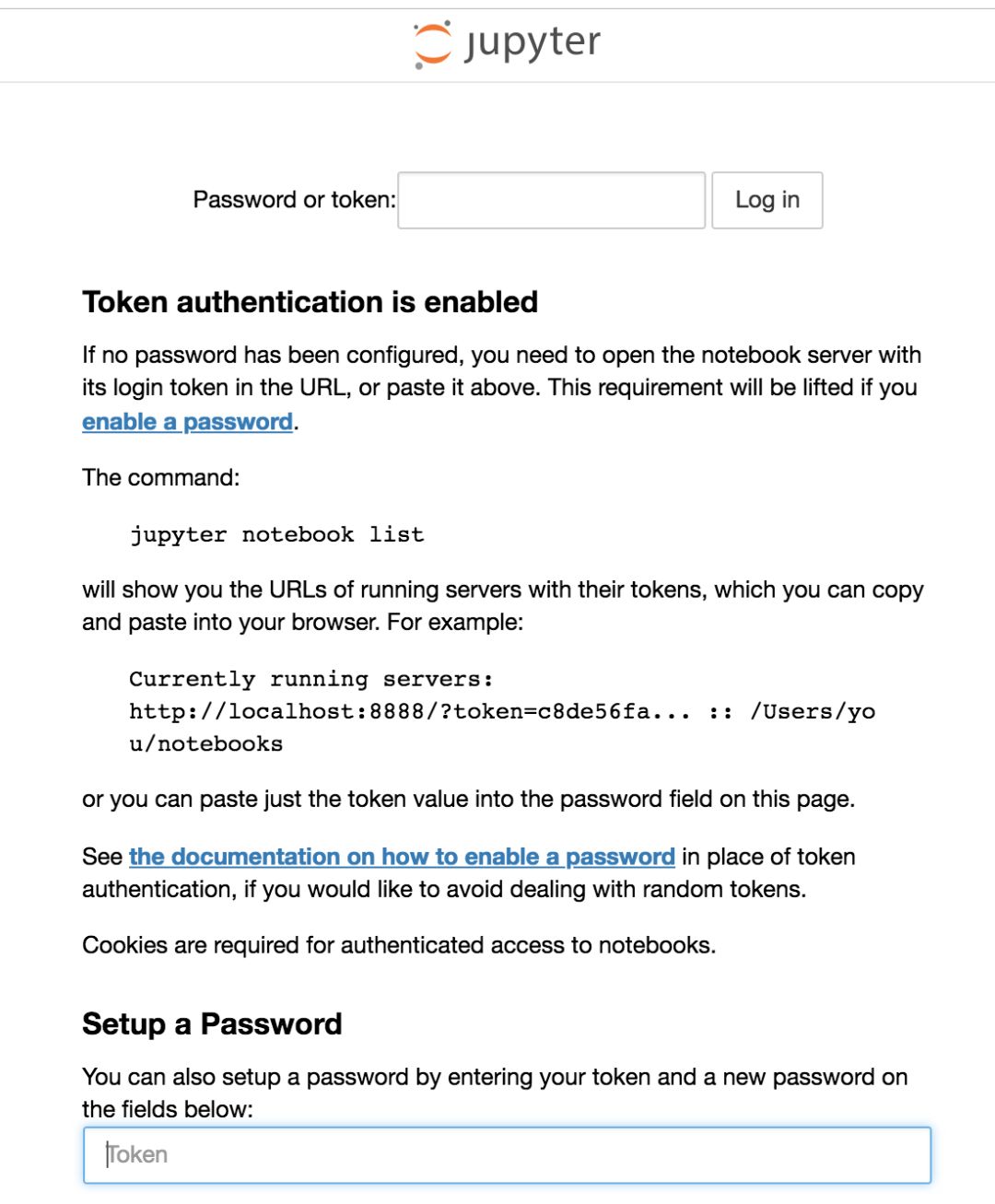
启动之后浏览器就会跳出url :http://127.0.0.1:8888/tree 的页面,那就是该编辑器的页面,修改启动notebooks 在本地路径:
jupyter notebook –generate-config // 获取在电脑上的配置文件
1
2
输入命令后,得到配置文件路径:
Writing default config to: /Users/znss/.jupyter/jupyter_notebook_config.py
1
如果此文件是隐藏文件,mac 电脑下可能看不到,可以用vi打开该配置文件,或者设置显示隐藏文件,这样你就可以用sublime text 软件打开,主要是修改文件中的一个配置项:
## 用于笔记本和内核的目录。
c.NotebookApp.notebook_dir = ‘/Users/znss/Public/work/workspace/python/’
1
2
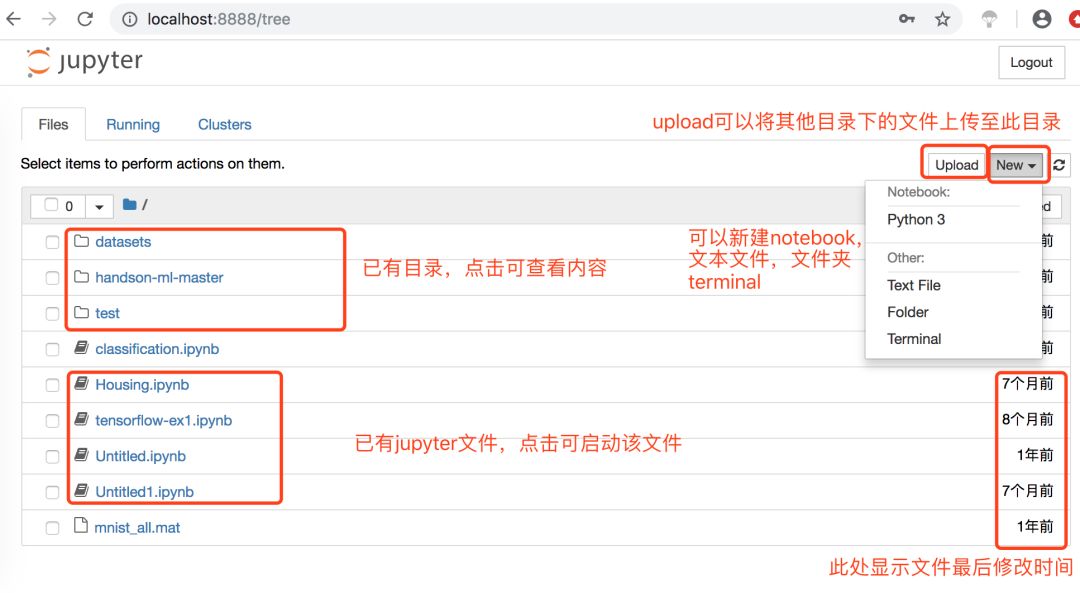
把这里的路径填写为你自己想要设置的路径就可以了,这样每次打开都会去找这个路径。
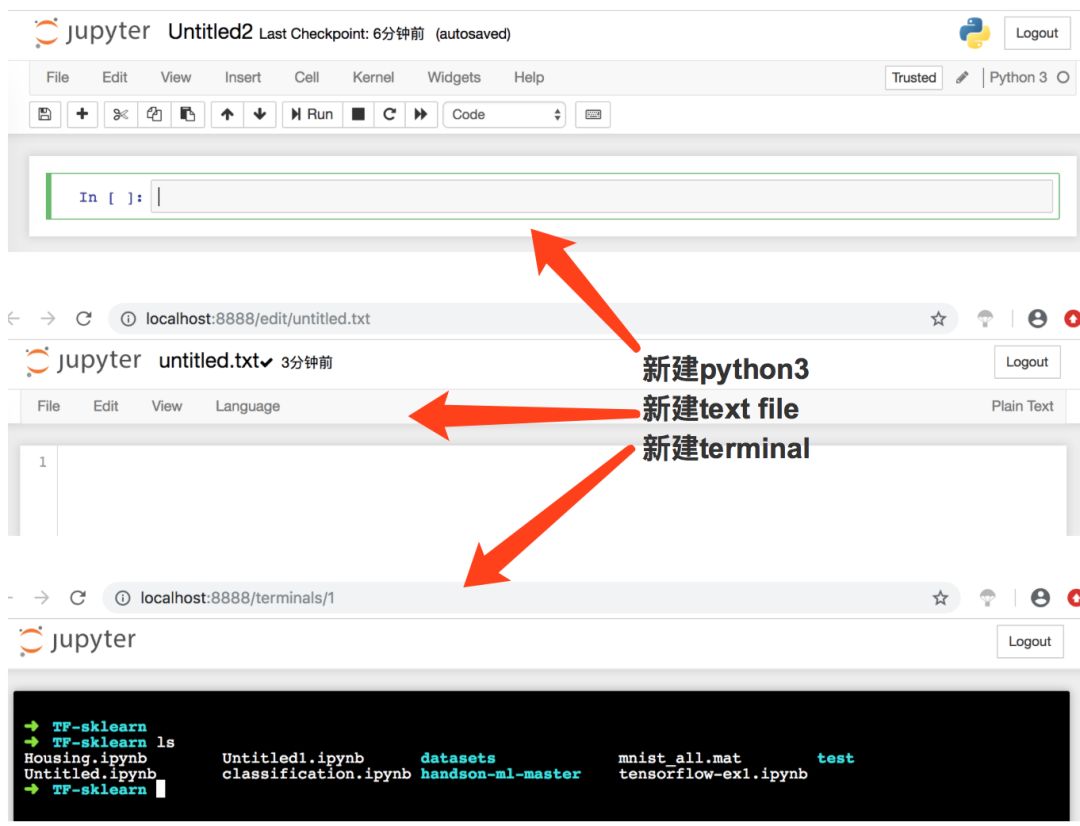
同时为了让jupyter notebook 可以使用conda创建的多个环境,如图所示:
使用conda安装插件,命令如下所示:
conda install nb_conda
1
插件一路yes 之后安装完毕,你可以启动,另一种方式:
python -m ipykernel install –user –name py3 –display-name “py3”
1
2
存在的问题
1、本地用pip 安装的库包,conda 创建的环境是不是都可以用?
2、conda base环境下安装的库包,是不是conda其他环境都可以用
3、进而存在,移除base包,其他所有创建的环境是不是都失效了,没有了环境?
————————————————
anaconda下改变python的版本
根据网页:http://python.jobbole.com/87522/
使用以下命令创建新环境:
conda create -n env_name list of packages
其中 -n 代表 name,env_name 是需要创建的环境名称,list of packages 则是列出在新环境中需要安装的工具包。
比如我现在的python版本是3.7,但是我想安装一个python 3.6的环境,则在anaconda prompt输入:
conda create -n py36 python=3.6
控制台会输出:
以及
# To activate this environment, use
#
# $ conda activate py36
#
# To deactivate an active environment, use
#
# $ conda deactivate
1
2
3
4
5
6
7
还是很酷很方便的。
现在激活这个新配置的环境:conda activate py36
输入python –version,可以看到:
(py36) C:\Users\dehen>python –version
Python 3.6.6 :: Anaconda, Inc.
(py36) C:\Users\dehen>
1
2
3
4
这时候打开anaconda navigator,发现多出来一个环境选择,太酷了。
这时候install 这个spyder就可以运行3.6版本下的程序了。
索性再配置一个python2.7的新环境:conda create -n py27 python=2.7
很快就显示配置完成并输出提示:
# To activate this environment, use
#
# $ conda activate py27
#
# To deactivate an active environment, use
#
# $ conda deactivate
1
2
3
4
5
6
7
所以,这样看来确实很方便,各个环境互相独立,都放在文件夹 D:\software\anaconda\envs 下:
还有,如果要删除我们配置的新环境,则:
conda env remove -n env_name
显示所有环境:
conda env list
当分享代码的时候,同时也需要将运行环境分享给大家,执行如下命令可以将当前环境下的 package 信息存入名为 environment 的 YAML 文件中。[6]
conda env export > environment.yaml
同样,当执行他人的代码时,也需要配置相应的环境。这时你可以用对方分享的 YAML 文件来创建一摸一样的运行环境。
conda env create -f environment.yaml
————————————————
anaconda没有重命名命令,因此使用克隆删除的方法
(1)进入旧环境
conda activate old_name
(2)克隆旧环境
conda create -n new_name –clone old_name
(3)退出旧环境
conda deactivate
(4)查看clone结果
conda info –envs
(5)删除旧环境
conda remove -n old_name –all
(6)查看最终结果
conda info –envs
————————————————
版权声明:本文为CSDN博主「不要清汤锅」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hello_program_world/article/details/111054427

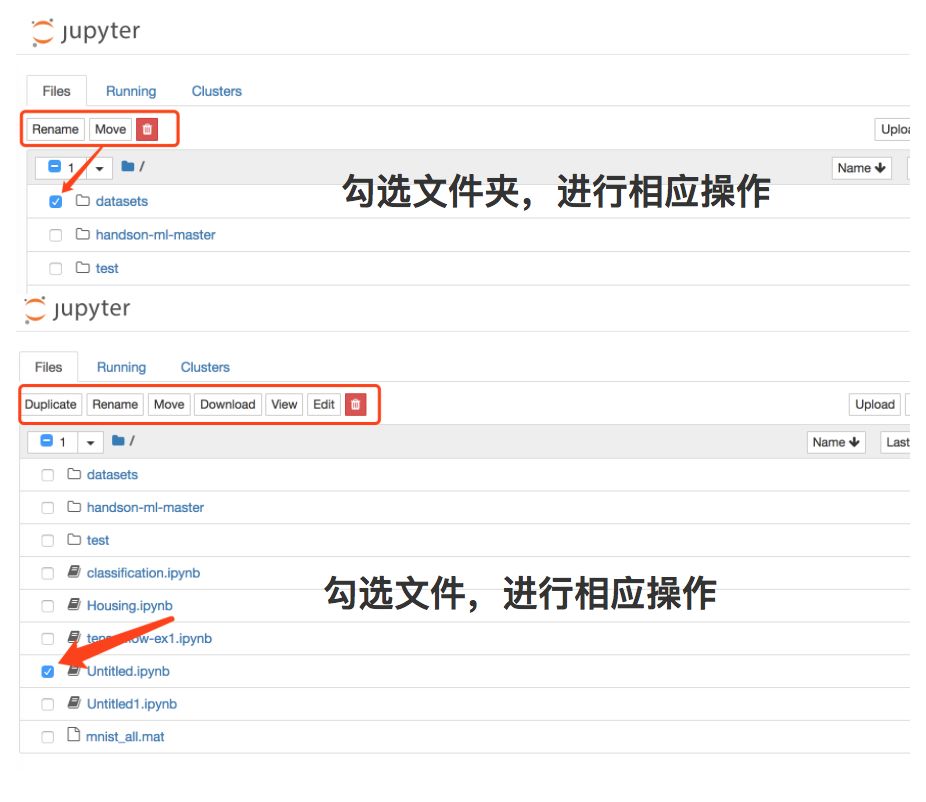
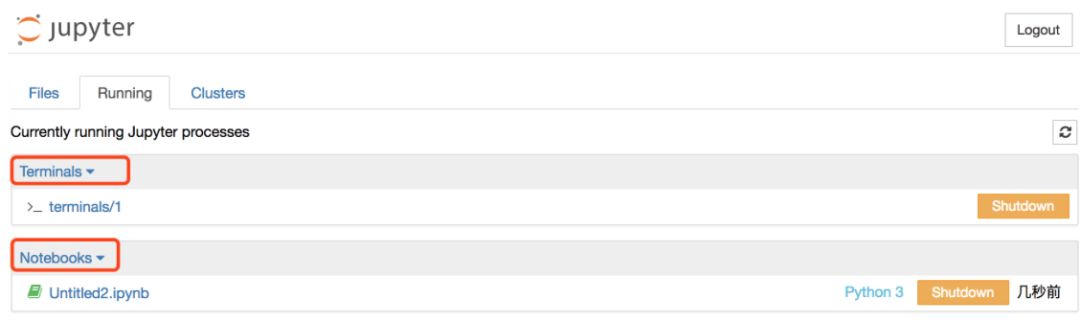
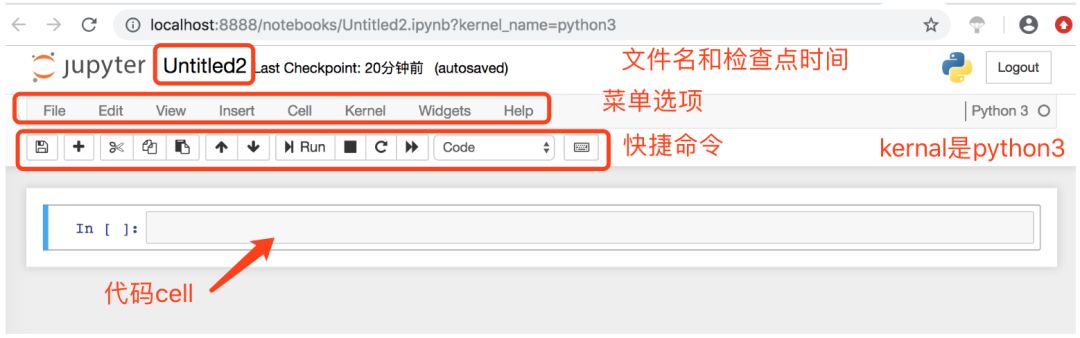
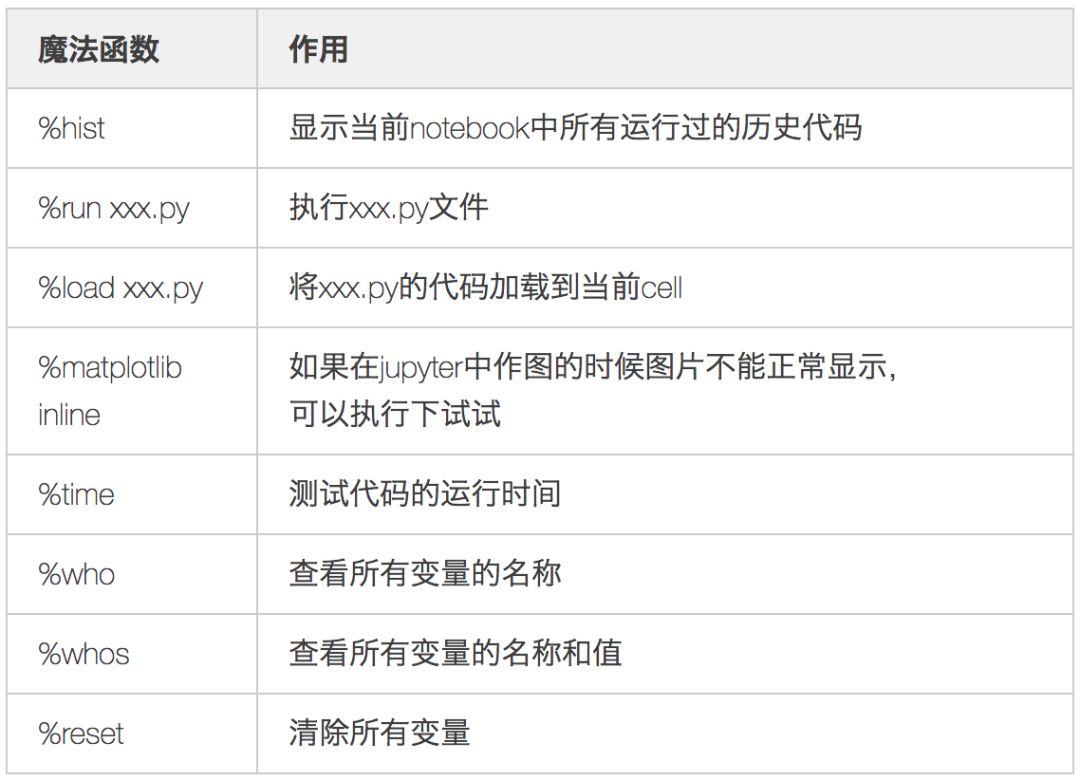
 4. 常用快捷(键)操作:
4. 常用快捷(键)操作: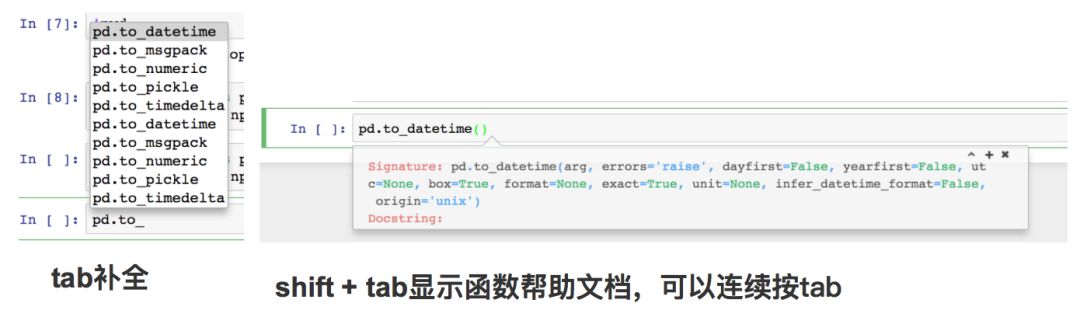





一键脚本检测你的vps是否解锁Netflix