HTML代码如下:
<ul class=”sf-r-list”>
<li>
<a href=”/book/77″ class=”sc-list-cover fl”>
<img class=”ba_page_prvimg” onload=”baImgCenter(this)” badt_outwidth=”” src=”https://wqxuetang.oss-cn-beijing.aliyuncs.com/cover/0/0/77/77.jpg!m”>
</a>
<div class=”sf-r-info”>
<h3 class=”sf-r-infotit”><a href=”/book/77″ class=”ellipsis-2″>Android多媒体开发高级编程——为智能手机和平板电脑开发图形、音乐、视频和富媒体应用</a>
</h3>
<p class=”sf-r-infoau text-truncate”> (美) 艾佛瑞 (Every,S.V.)…</p>
<p class=”sf-r-infotext ellipsis-2″>《Android多媒体开发高级编程》使用清晰、直观的示例介绍了Android SDK中丰富的多媒体功能,有助于您开发能够创建、播放和共享多媒体的优秀Android应用程序。许多Android设备本身就是照相机、相册、…</p>
<div class=”sf-r-infoprice”>
<span style=”color:#8E9AA6;”> 暂不销售</span>
</div>
</div>
</li>
…<!– 与前述<li> .. </li>类同 –>
…
<li style=”float:none;margin:0;display:block;clear:both;”></li>
</ul>
需要把<ul> …</ul直接的列表项中的信息抓取出来,其中每个列表项包含书籍的名称、作者、简介和价格信息。我最初使用的代码如下:
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen(‘https://wqbook.wqxuetang.com/category/tid_2004/pid_/pn_1014.html’)
bs = BeautifulSoup(html,’lxml’)
book_ul = bs.find(“ul”,class_=”sf-r-list”)
book_lis = book_ul.find_all(“li”)
for item in book_lis:
print(item.prettify())
但是抓取的列表项中总会包含:
<li style=”float:none;margin:0;display:block;clear:both;”></li>
1
当时在BeautifulSoup的函数find_all()中的参数上想了一些办法,因为我预感对标签的筛选肯定在参数中有所体现。可是都不成功。在我读到的爬虫书籍中,对此场景的技术方案都没讲解。无奈最后我采用了笨方法将<li style=”float:none;margin:0;display:block;clear:both;”></li>剔除出去,代码如下:
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen(‘https://wqbook.wqxuetang.com/category/tid_2004/pid_/pn_1014.html’)
bs = BeautifulSoup(html,’lxml’)
book_ul = bs.find(“ul”,class_=”sf-r-list”)
book_lis = book_ul.find_all(“li”)
for item in book_lis:
if book_li.find(“a”):
print(item.prettify())
亦即,我是通过判断在标签<li></li>是否包含子标签<a></a>来完成的。当时也顺利完成了爬虫的功能。但这个问题在我脑中记录下来了。直到今天,读书籍《Web Scraping with Python》第二版1的85页代码时,发现:
downloadList = bs.findAll(src=True)
1
受启发,可以用到本文场景中。当时书上也没讲解src=True的含义。
优雅的解决方案
在BeautifulSoup的函数find_all()中的参数中设置某个属性值为False或True,允许我们在匹配时控制某个属性在标签中是否出现,以此来匹配查找。于是,本应用场景的优美解决方案为:
# scrapeBookInfoUnitTest.py
# 2020-08-20
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen(‘https://wqbook.wqxuetang.com/category/tid_2004/pid_/pn_1014.html’)
bs = BeautifulSoup(html,’lxml’)
book_ul = bs.find(“ul”,class_=”sf-r-list”)
#book_lis = book_ul.find_all(“li”)
book_lis = book_ul.find_all(“li”,style=False)
for item in book_lis:
————————————————
版权声明:本文为CSDN博主「hbqjzx」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hbqjzx/article/details/112444210
为了将comments下的所有用户评论选出来

每一个<li>标签代表一个用户的评论,就直接用find_all(‘li’)了
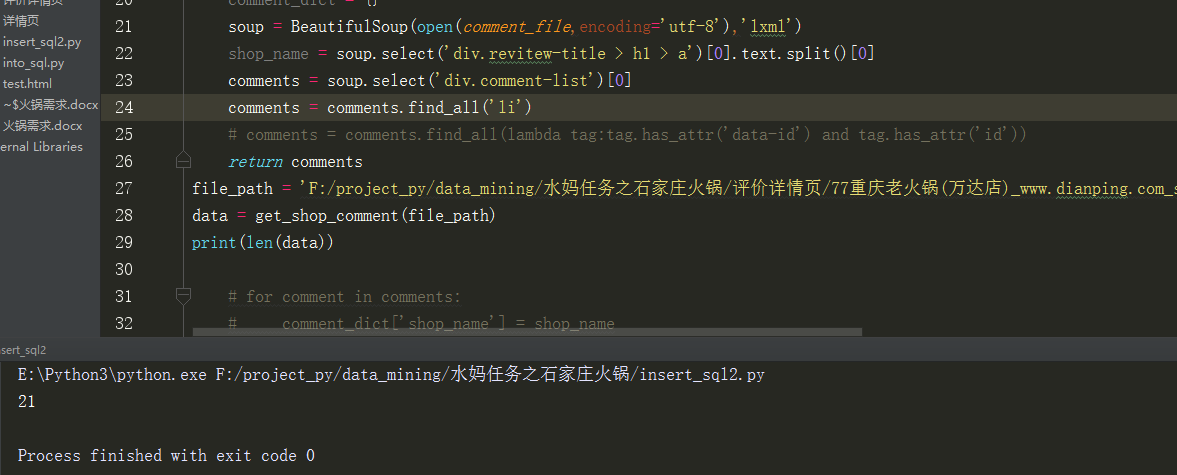
但发现这里有21项,但数了数发现只有20个用户,原来啊是这里出问题了:
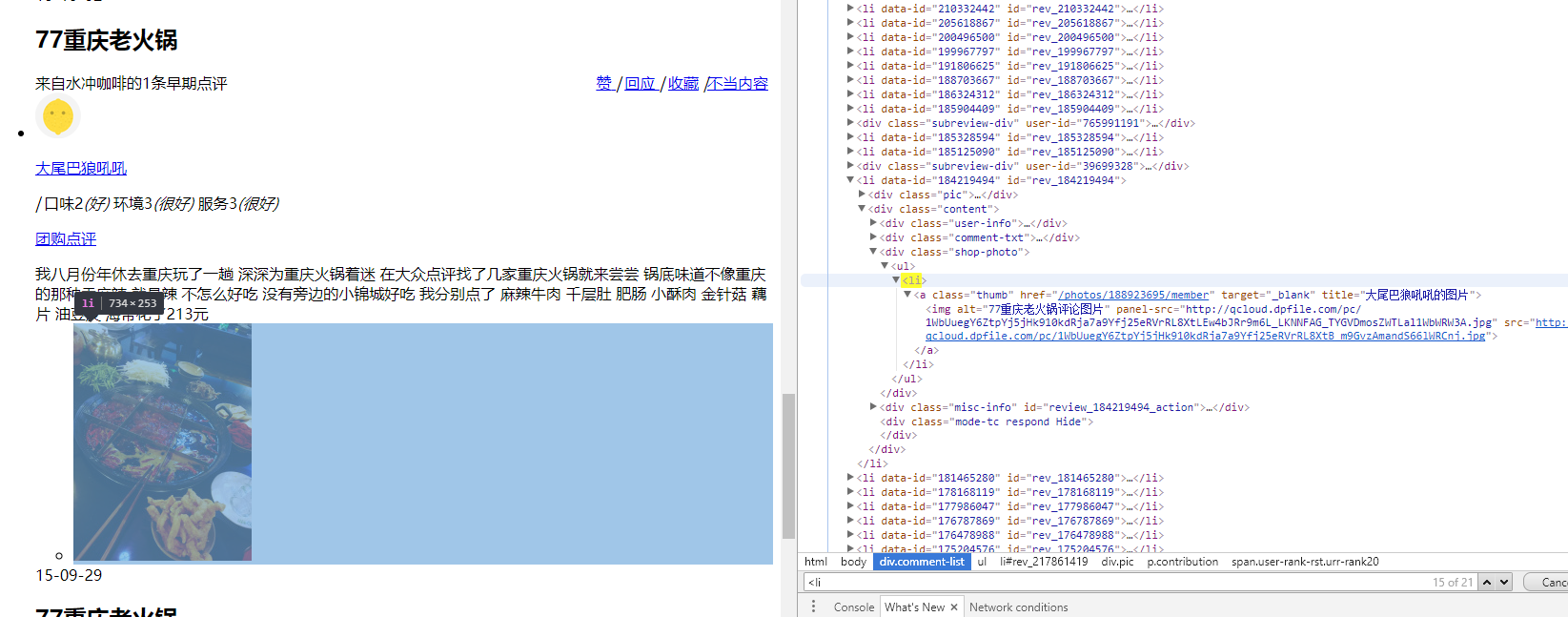
这个li标签是用户评论下的一张图片。
但我们不想选到这个,观察一下,用户的li含有“data-id”和“id”属性,而图片没有,如下图:
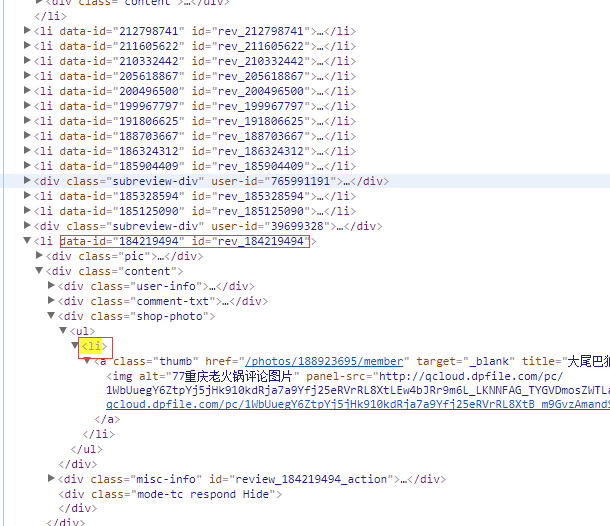
于是就去百度找了一下“beautifulsoup find_all怎样把带有某种属性的标签选出而不含该属性的标签不选”但没找到结果,
先是试了试在find_all加入属性,想匹配出含有”data-id”属性的“li”标签,但试了几个都出问题,就感觉这个方法行不通。
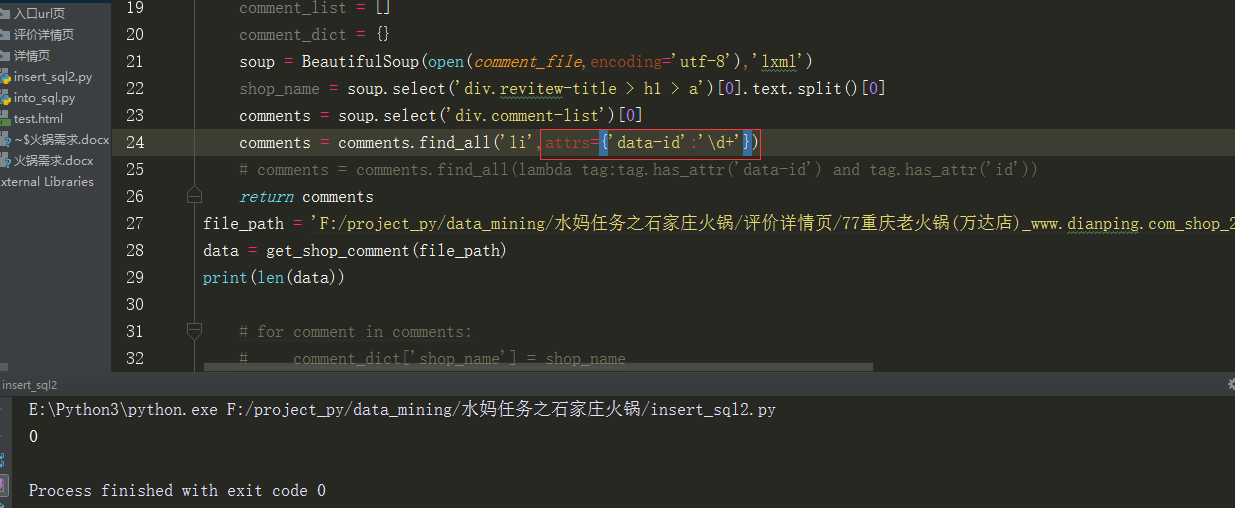
最后通过翻阅beautifulsoup官方文档,发现一个find_all传方法:
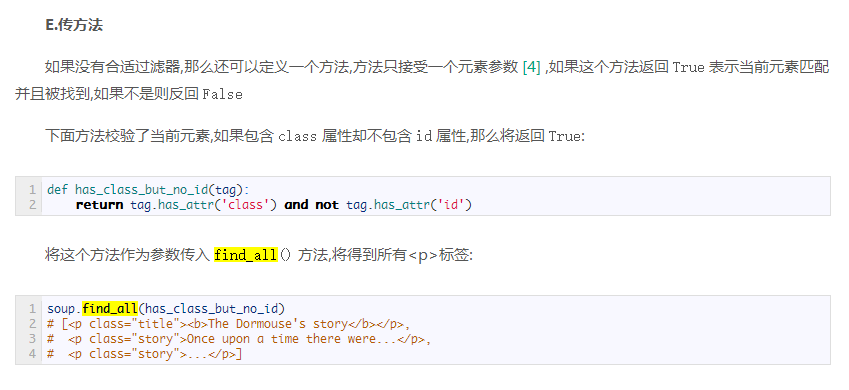
于是自己也写了一个方法,正好把所有符合条件的都选了出来了
1 soup = BeautifulSoup(open(comment_file,encoding='utf-8'),'lxml')
2 comments = soup.select('div.comment-list')[0]
3 comments = comments.find_all(lambda tag:tag.has_attr('data-id') and tag.has_attr('id'))
如下
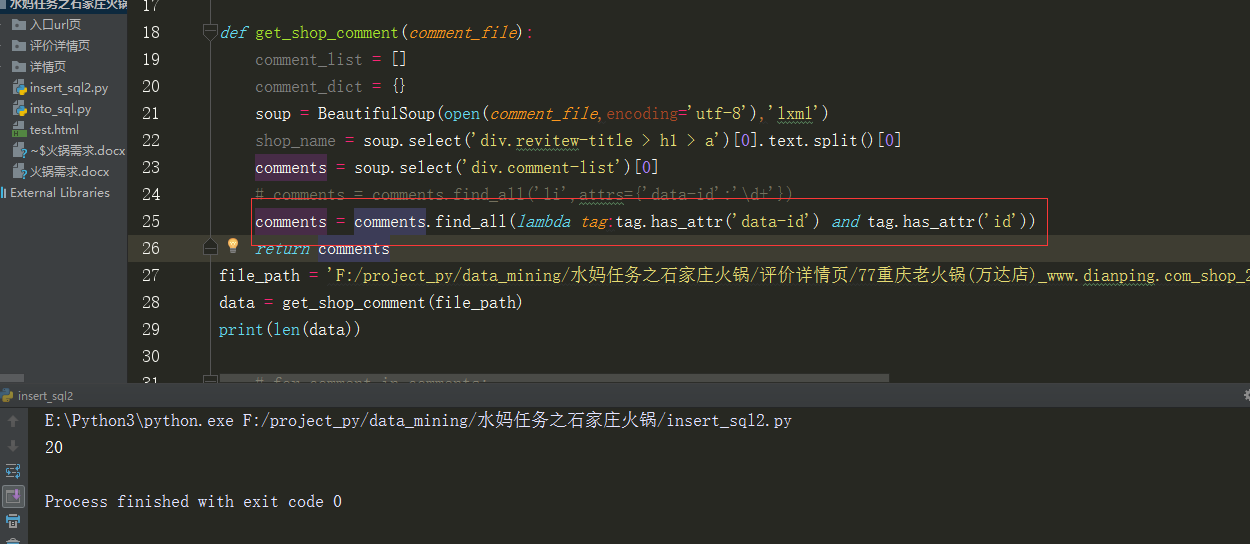
后来又阅读了一下官方文档,
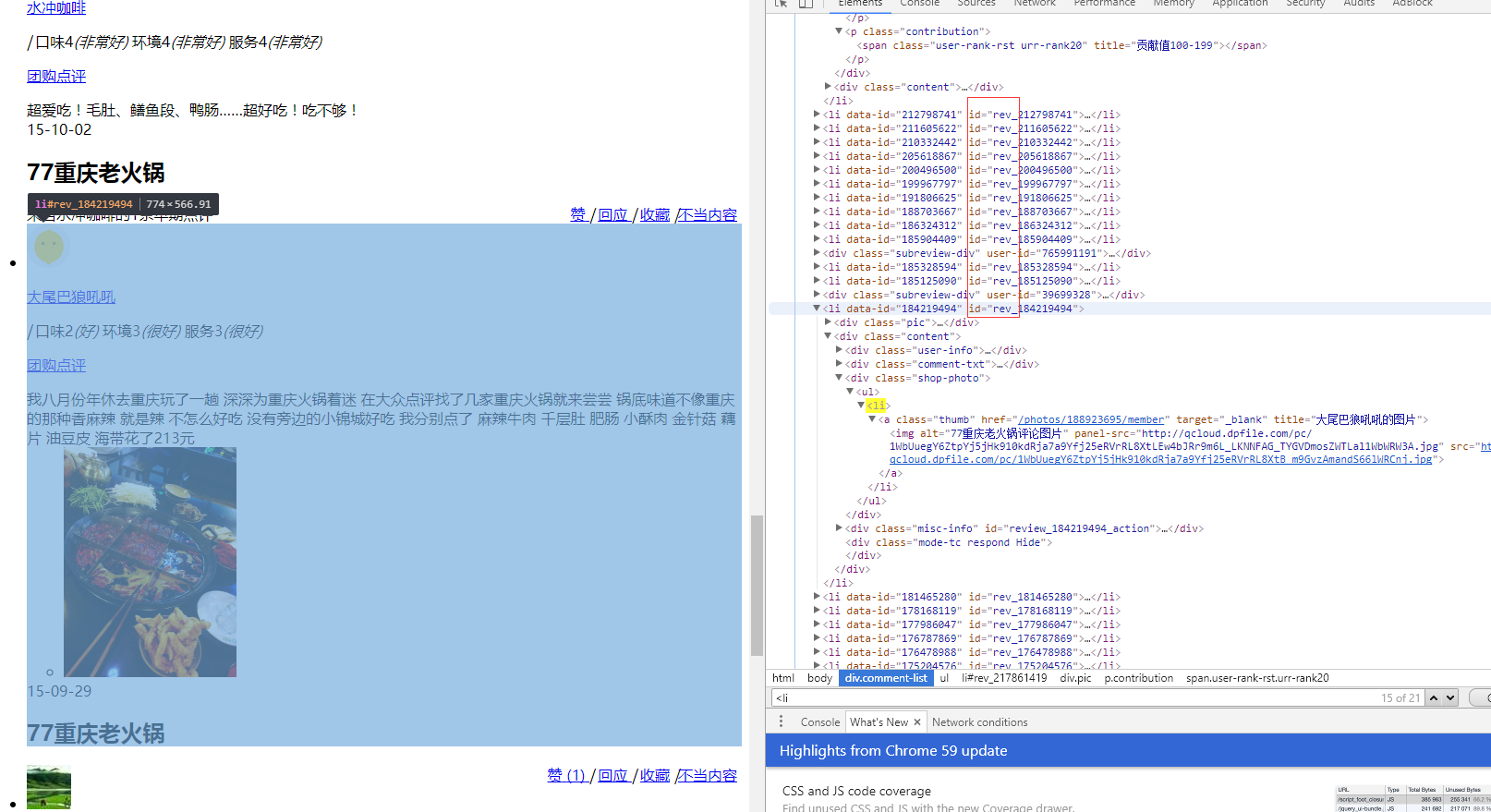
发现这些用户的li都含有id属性,且“id”均含“rev_”开头,所以试了下正则表达式:
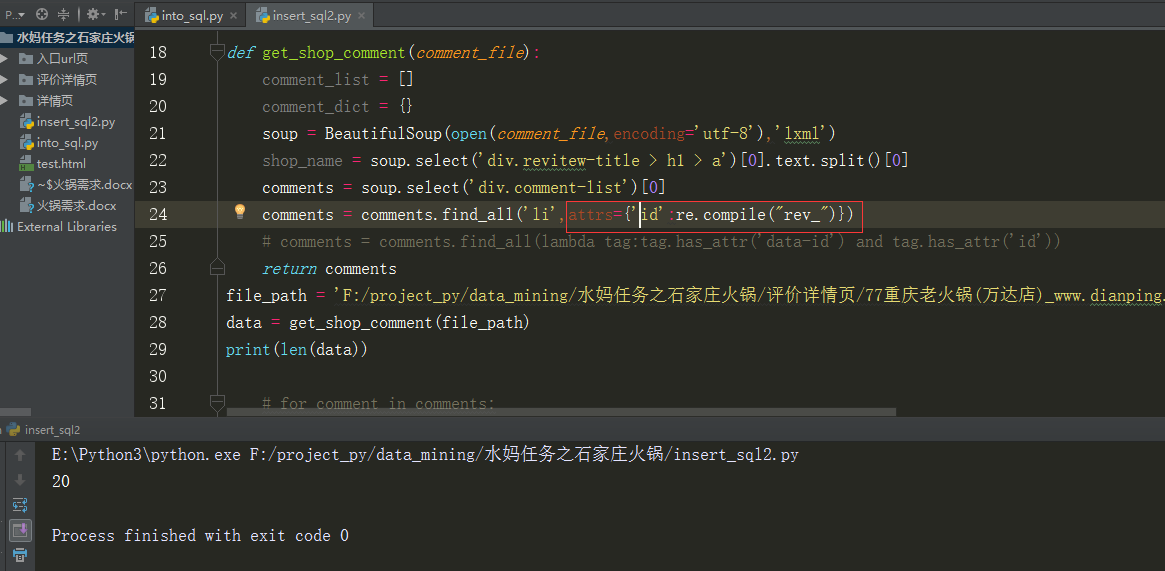
也正确的把他们都选出来了!
时隔半年再来写这个小爬虫,还是挺吃力啊!所以还是学了之后要多用,多巩固,才能迎刃而解!